前言
本文档尚在编写和调整中
随着信息技术的迅猛发展,操作系统作为计算机系统的基石和核心软件,其地位日益显著。在这样一个时代背景下,中科院软件所/中科南京软件技术研究院团队凭借其深厚的科研实力,基于我国自主研发的开源操作系统openEuler,精心打造了一款高性能、安全、易用的操作系统——傲来操作系统(EulixOS)。这款操作系统不仅凝聚了我国软件领域的最新科研成果,更在满足开源爱好者、科研人员以及学生们需求的同时,为在线服务、高性能计算、AI计算等多元化使用场景提供了卓越的体验。
为了进一步推广和普及傲来操作系统,让更多人了解并掌握这一先进技术,我们特别策划并举办了傲来操作系统训练营。此次训练营旨在为广大参与者提供一个系统学习、实践操作的平台,帮助他们在短时间内掌握傲来操作系统的使用方法。本书正是为此训练营的学员量身定制的学习引导手册,从导学阶段开始,为学员们的学习之路保驾护航。
本书采用mdbook进行编写,以简洁明了的排版风格,便于学员阅读与学习。同时,我们已将本书部署至线上地址:https://kunyuanxu-star.github.io/eulix-camp-book-stage0/,让学员们可以随时随地进行学习,充分利用碎片时间提升自己。此外,我们还为学员们提供了详尽的本地使用方法,确保在无法访问网络的情况下,学员们依然可以通过本地文档进行自学。
在内容编排上,本书首先对傲来操作系统的基本情况以及训练营的概况进行了详细介绍,让学员对整个学习过程有清晰的认识。随后,本书逐步引导学员进行环境配置、Git使用、前置知识学习等准备工作,为后续学习打下坚实基础。在此基础上,通过一系列精心设计的实验题目,帮助学员们掌握基本的编程技能,并熟练运用傲来操作系统。最后,本书还提供了晋级后的拓展内容、后续学习指引以及常见问题解决方案,助力学员们在操作系统领域不断深入探索。
我们衷心希望本书能成为学员们学习傲来操作系统的得力助手,陪伴他们在实践中不断进步,为我国操作系统的研究和应用贡献自己的力量。同时,我们也期待与各位学员共同探讨、交流,共同推动傲来操作系统的发展和完善,为我国软件产业的发展献出一份力量。
介绍
傲来操作系统(EulixOS)是由中科院软件所 / 中科南京软件技术研究院团队基于 openEuler 打造的操作系统发行版,其开发目标是集成软件所的最新科研成果,面向开源爱好者、科研人员和学生,为在线服务、高性能计算、AI 计算等使用场景提供一款安全、易用的操作系统。
本书用于为参与傲来操作系统训练营的学员提供导学阶段学习引导。
本书基于 mdbook 编写,已部署至 https://kunyuanxu-star.github.io/eulix-camp-book-stage0/
文档本地使用方法
需要 Rust 环境。
git clone https://github.com/kunyuanxu-star/eulix-camp-book-stage0.git
cd arceos-tutorial-book
cargo install mdbook
mdbook serve docs
文档大纲
- 前言
- 介绍
- 环境配置
- 第一章:导学阶段基本信息
- 训练营教学系统使用引导
- 导学阶段视频课程链接与学习引导
- 导学课程学习资料汇总
- 开营仪式教学安排与资料汇总
- 教学系统常见问题与解决方案
- 第二章:基本 Git 使用与 Gitee 流水线入门
- 常用 Git 指令
- Gitee 使用入门
- Gitee Go 的配置与使用
- 流水线常见问题与解决方案
- 第三章:前置知识
- Linux 使用入门与配置
- C 语言基本语法
- make 基本使用与 Makefile
- 如何在非 Linux 环境中完成实验
- 第四章:开始实验
- 实验代码框架讲解
- 本地测试流程
- 实验相关资料汇总
- 第一题:输出 Hello World!
- 第二题:基本循环
- 第三题:打印九九乘法表
- 第四题:求素数
- 第五题:约瑟夫环
- 导学阶段实验相关问题与解决方案
- 第五章:提交成绩
- 流水线测试过程
- 排行榜成绩查看与绑定
- 如何晋级
- 提交过程相关问题与解决方案
- 第六章:晋级之后
- 拓展内容汇总
- 后续学习指引
- 部分优质实践资源
- 其余常见问题与解决方案
- 附录A:使用 Gitee 流水线信息进行调试
- 附录B:实验所用到的其余专业前置知识
- 附录C:部分工具的使用入门
环境配置
为了顺利进行导学阶段的实验,为之后正式学习的实验做好准备,需要先进行一些简单的环境配置。
我们推荐在 Linux 环境下完成实验,如果不在 Linux 环境下完成实验可能会遇到部分问题,具体可参考如何在非 Linux 环境中完成实验。
配置 Git
实验的最终成绩需要提交到远程 Gitee 仓库进行评测,你需要确保本地拥有 Git。
Ubuntu/Debian 发行版安装 Git:
sudo apt install git
Arch 发行版安装 Git:
sudo pacman -Syu git
Windows 下需要安装 Git for Windows,可从如下链接安装:
https://gitforwindows.org/
在完成 Git 的安装后需要对 Git 进行基本的配置:
git config --global user.name "你的 gitee 账户名/自定义"
git config --global user.email "你的 gitee 账户默认的邮箱地址/常用邮箱地址"
配置 C 工具链
导学阶段实验由5到基础的 C 语言语法题组成,为了完成实验以及在本地进行调试,需要配置 C 工具链。
Ubuntu/Debain 发行版配置:
sudo apt install build-essential gdb #安装 GNU 工具链与调试工具
Arch 发行版配置:
sudo pacman -S base-devel gdb
Windows 需要安装 mingw 等编译工具链。
mingw 官网:https://www.mingw-w64.org/
在完成安装之后,可使用如下指令检测 gcc 是否被正确配置:
gcc --version
至此,导学阶段实验所需要的基本环境配置已完成,接下来,让我们正式进入导学阶段的学习。
导学阶段基本信息
本章节介绍导学阶段的基本信息,主要内容如下:
训练营教学系统使用引导
训练营教学系统导学阶段链接
个人信息管理
如图所示,通过右上角显示的昵称,选择个人中心,进入个人信息管理。
通过这里的编辑个人信息可以对自己的信息进行补充和修改。
注:为了确保实验成绩在排行榜上正确显示,请确保正确填写了 GitHubName/GiteeName。
如何听课
1.首先,你需要进行课程签到,如未完成签到,签到按钮会显示于红圈内“已签到”位置。
2.完成签到后可在上课时间点击“进入教室”听课,课程回放会在直播课程结束后于“学习视频”页面上架。
教室使用
进入教室时需要确保给与当前页面足够的权限。
如有需要可通过左下角聊天框向老师提问。
如发现电脑端听课不便,可通过右上角“手机听课”在手机端听课。
注:请优先使用 Chrome 浏览器听课。
成绩查看
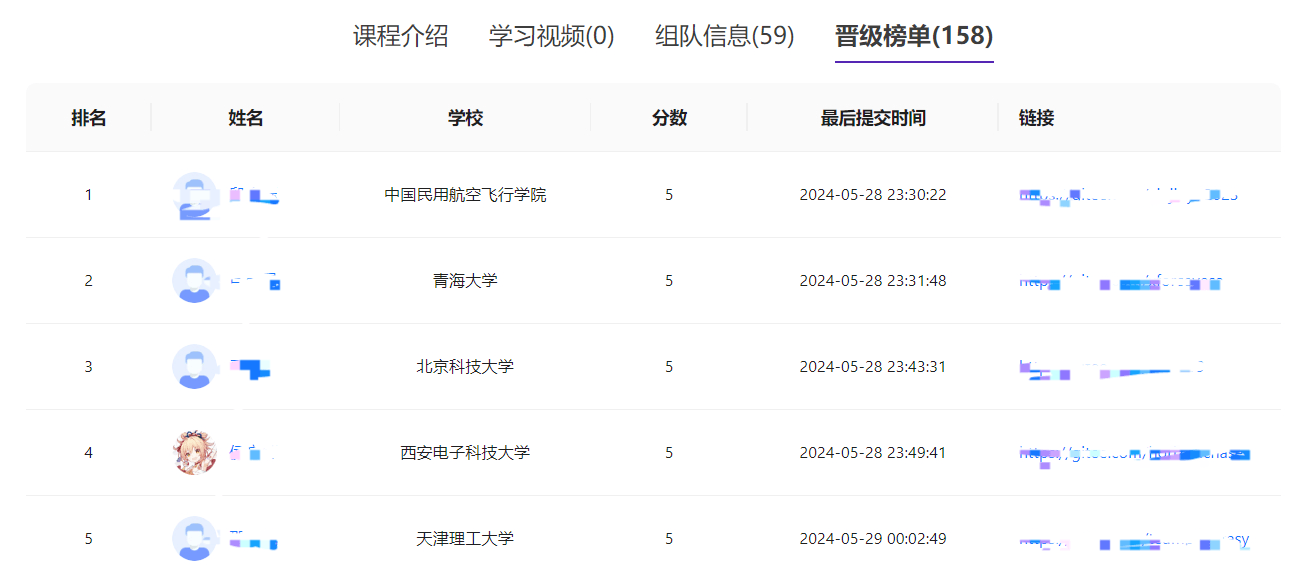
实验的最终成绩会显示在晋级榜单页面,此处会显示排名、姓名(授课系统昵称)、学校(如在个人信息内填写)、分数与其他信息。
排行榜上显示的成绩将会作为个人晋级的依据。
组队
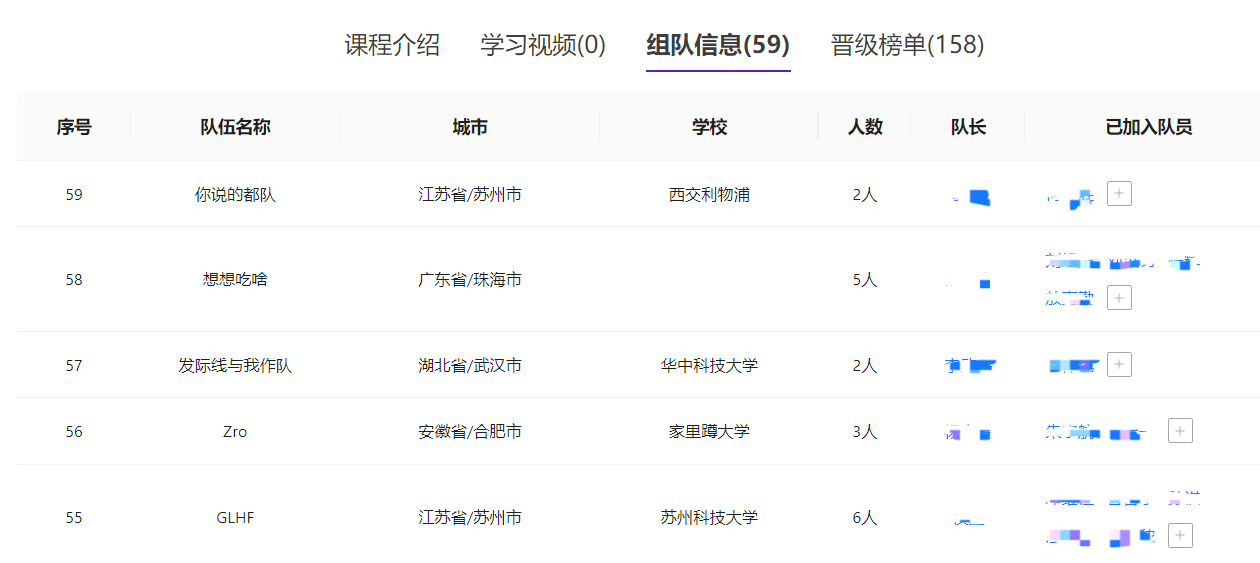
训练营允许且鼓励学员组队学习,组队的操作位于“组队信息页面”。关于组队的操作说明如下:
- 只有队长可以创建/解散队伍,其余队员只可加入退出。
- 包含队长在内,不少于两人的队伍为有效组队,不允许“单人成队”。
- 训练营为全员晋级的队伍的队长发放奖品作为鼓励。
- 组队情况不影响单人晋级。
导学阶段视频链接与学习引导
在导学阶段,我们使用《循序渐进,学习开发一个 RISC-V 上的操作系统》系列课程作为导学的网络课程,帮助您学习和掌握与RISC-V相关的指令、操作系统知识。
该系列课程的视频回放上传至 bilibili 上,通过访问《循序渐进,学习开发一个 RISC-V 上的操作系统 》课程录像 进行观看学习。
全部课程的课件位于码云上的《循序渐进,学习开发一个 RISC-V 上的操作系统 》课件,可以通过浏览器访问或对该仓库进行克隆。
| 编号 | 课程 | 时长 | 链接 |
|---|---|---|---|
| 1 | 导论 | 25分钟 | 链接 |
| 2 | 计算机系统漫游 | 53分钟 | 链接 |
| 3 | RISC-V ISA 介绍(上) | 36分钟 | 链接 |
| 4 | RISC-V ISA 介绍(下) | 1小时6分钟 | 链接 |
| 5 | 编译与链接 | 44分钟 | 链接 |
| 6 | 嵌入式开发介绍 | 34分钟 | 链接 |
| 7 | RISC-V 汇编编程(第一部分) | 28分钟 | 链接 |
| 8 | RISC-V 汇编编程(第二部分) | 43分钟 | 链接 |
| 9 | RISC-V 汇编编程(第三部分) | 43分钟 | 链接 |
| 10 | RISC-V 汇编编程(第四部分) | 41分钟 | 链接 |
| 11 | RISC-V 汇编编程(第五部分) | 25分钟 | 链接 |
| 12 | RISC-V 汇编编程(第六部分) | 44分钟 | 链接 |
| 13 | RISC-V 汇编编程(第七部分) | 57分钟 | 链接 |
| 14 | RISC-V 汇编编程(第八部分) | 17分钟 | 链接 |
| 15 | RVOS 介绍 | 15分钟 | 链接 |
| 16 | Hello RVOS(上) | 38分钟 | 链接 |
| 17 | Hello RVOS(下) | 57分钟 | 链接 |
| 18 | 内存管理 | 55分钟 | 链接 |
| 19 | 上下文切换与协作式多任务 | 38分钟 | 链接 |
| 20 | Trap 与 Exception | 1小时7分钟 | 链接 |
| 21 | 外部设备中断 | 42分钟 | 链接 |
| 22 | 硬件定时器 | 15分钟 | 链接 |
| 23 | 抢占式多任务 | 37分钟 | 链接 |
| 24 | 任务同步和锁 | 1小时2分钟 | 链接 |
| 25 | 软件定时器 | 32分钟 | 链接 |
| 26 | 系统调用 | 45分钟 | 链接 |
导学课程学习资料汇总
课程相关学习资料
导学阶段课程课件
riscv-operating-system-mooc/slides
此链接包含导学阶段课程《循序渐进,学习开发一个 RISC-V 上的操作系统 的全部课件,可作为视频课程的辅助之用。
课程配套实验
此链接为导学阶段课程的配套实验代码仓库,实验难度不大,适合初学者了解系统编程与操作系统理论知识,推荐尝试。
一个可运行课程实验的 RISCV CPU
此仓库为一位该课程《循序渐进,学习开发一个 RISC-V 上的操作系统 》 的热心学员设计的 RISCV CPU,可在其上运行课程配套的实验代码。
课程代码到物理机的移植记录
riscv-operating-system-mooc/issues/I64EEQ
这里记录了该课程配套代码向物理机的移植记录,鼓励大家在完成本课程后积极参与这一活动,提高自己的系统编程与工程能力。
一份来自b站本课程学员的学习笔记
RISC-V入门(基础概念+汇编部分) 基于 汪辰老师的视频笔记
其余学习资料
uCore 实验指导书
uCore 实验同样为实现一个 RISCV 架构操作系统的教学用操作系统,其难度较于导学阶段课程颇高,但是内容完善,体系严整,可作为完成课程后的提高之用。
rCore 实验指导书
rCore 实验与 uCore 实验内容基本相同,但是 rCore 代码框架使用 Rust 语言编写,欲进行实验需要先行学习 Rust,但通过本实验可以学习 Rust base OS 这一新兴技术,建议学有余力的学员进行尝试。
清华大学操作系统课程资料
此链接整合了清华大学计算机系2024春季学习操作系统课程课堂幻灯片的主要内容,对幻灯片中的一些概念进行了简单补充。
开营仪式教学安排与资料汇总
训练营开营启动会
会议时间:2024/06/02 20:00视频回放(密码:0602)
训练营开营启动会安排
-
8:00 主持人唐涵主持开场,介绍与会老师与嘉宾
-
8:02 武延军所长致辞
-
8:07 陈渝老师致辞
-
8:12 于佳耕老师致辞,介绍 RISC-V 当前生态及未来发展方向展望
-
8:27 常秉善介绍本次训练营报名及课程开设介绍
-
8:42 王凡介绍本次训练营的基础与专业阶段并分享学习经验
-
8:57 姬晨晨介绍本次训练营项目阶段的选题方向和实践
-
9:12 于佳耕老师总结寄语
-
9:15 主持人介绍组队宣传,及引导训练营问题答疑
训练营教学安排
傲来操作系统(EulixOS)官网
傲来操作系统1.0使用手册
教学系统常见问题与解决方案
在使用教学系统进行学习或参与活动时,可能会遇到各种技术问题。以下是一些常见问题的解决方案,帮助你顺利完成学习任务和活动参与。
1.pc 端教室画面显示异常
如果在使用 Edge 浏览器时遇到教室画面显示不全的问题,可以尝试切换到 Chrome 浏览器。Chrome 浏览器通常对网页的兼容性更好,可以有效避免显示问题。
建议在 PC 端使用 Chrome 浏览器听课,以防止出现类似问题。
2.组队页面无法自己组建队伍
如果你发现自己无法在组队页面创建新的队伍,首先检查你是否已经加入或创建了另一支队伍。每个阶段通常限制每人只能参与一支队伍。如果已加入或创建了队伍,你需要先退出或解散当前队伍,然后才能创建新的队伍。
如果确认没有加入或创建其他队伍,但仍然无法创建新队伍,请确保你已经登录到教学系统。如果登录后问题依旧,建议联系系统管理员寻求帮助。
3.进入教室后发现没有声音
如果在进入教室后发现没有声音,首先检查你是否已经给予教室页面所需的权限,如麦克风和扬声器的访问权限。同时,检查你的本地设备设置,确保扬声器或耳机已正确连接并开启。
如果声音较小,可以在聊天区向授课老师提出,请求调整音量。
4.晋级榜单上的成绩没有准确链接到用户信息
为了确保你的成绩能够正确链接到你的用户信息,你需要在个人信息页面中正确填写你的 GitHubName 或 GiteeName。这些信息是用来识别你的身份并关联你的成绩的。
填写完毕后,重新提交你的代码。这通常可以刷新成绩和用户信息的链接,确保你的成绩正确显示在排行榜上。
基本 Git 使用与 Gitee 流水线入门
训练营的实验基于 Gitee 平台提供的 Gitee Go 服务进行在线的评测与成绩提交,因而本章简要介绍基本的 Git 使用与 Gitee Go 服务配置,以便于大家开展实验。
常用 Git 指令
Git 是一个强大的版本控制系统,广泛应用于软件开发中。以下是一些常用的 Git 指令,它们是日常工作中不可或缺的工具。
1. 初始化仓库
git init
这个命令会在当前目录创建一个新的 Git 仓库。执行后,目录下会生成一个 .git 子目录,用于存储仓库的元数据和对象数据库。
2. 克隆仓库
git clone <repository_url>
克隆远程仓库到本地。<repository_url> 可以是 HTTPS、SSH 或 Git 协议的 URL。例如:
git clone https://gitee.com/username/repository.git
克隆完成后,你将拥有一个与远程仓库完全相同的本地副本。
3. 添加文件
git add <file>
这个命令将工作目录中的文件添加到暂存区(staging area),准备进行下一次提交。例如:
git add README.md
你也可以使用 git add . 来添加所有更改过的文件。
4. 提交更改
git commit -m "commit message"
提交暂存区的文件到本地仓库,commit message 是对这次提交的描述。例如:
git commit -m "Add initial README file"
5. 查看状态
git status
这个命令显示工作目录和暂存区的状态。你可以看到哪些文件被修改,哪些文件被添加到暂存区,以及哪些文件未被跟踪。
6. 查看提交历史
git log
这个命令显示仓库的提交历史。默认情况下,它会显示每个提交的作者、提交时间、提交信息以及提交的哈希值。
7. 推送更改
git push origin <branch_name>
这个命令将本地仓库的提交推送到远程仓库。<branch_name> 是你想要推送的分支名称。例如:
git push origin master
8. 拉取更新
git pull origin <branch_name>
这个命令从远程仓库拉取更新并尝试合并到当前分支。<branch_name> 是远程分支的名称。例如:
git pull origin develop
9. 创建分支
git branch <branch_name>
这个命令创建一个新分支,但不会自动切换到该分支。例如:
git branch feature-x
10. 切换分支
git checkout <branch_name>
这个命令切换到指定的分支。例如:
git checkout feature-x
你也可以使用 git checkout -b <branch_name> 来创建并切换到新分支。
11. 合并分支
git merge <branch_name>
将指定分支的更改合并到当前分支。
12. 删除分支
git branch -d <branch_name>
删除指定的分支。
注意,如果分支有未合并的更改,Git 会阻止你删除它。
13. 撤销更改
git checkout -- <file>
这个命令撤销对文件的本地更改,将其恢复到最后一次提交的状态。例如:
git checkout -- README.md
14. 撤销暂存区的更改
git reset HEAD <file>
将文件从暂存区移出,但保留本地更改。
15. 撤销提交
git reset --hard <commit_hash>
撤销到指定的提交,<commit_hash> 是提交的哈希值。这将重置工作目录和暂存区,使其与指定的提交完全一致。
Gitee 使用入门
Gitee 是一个基于 Git 的代码托管和协作平台,它提供了代码仓库管理、代码审查、问题跟踪、持续集成和部署等功能。以下是 Gitee 使用的一些基本步骤和技巧。
Gitee 基本功能的使用
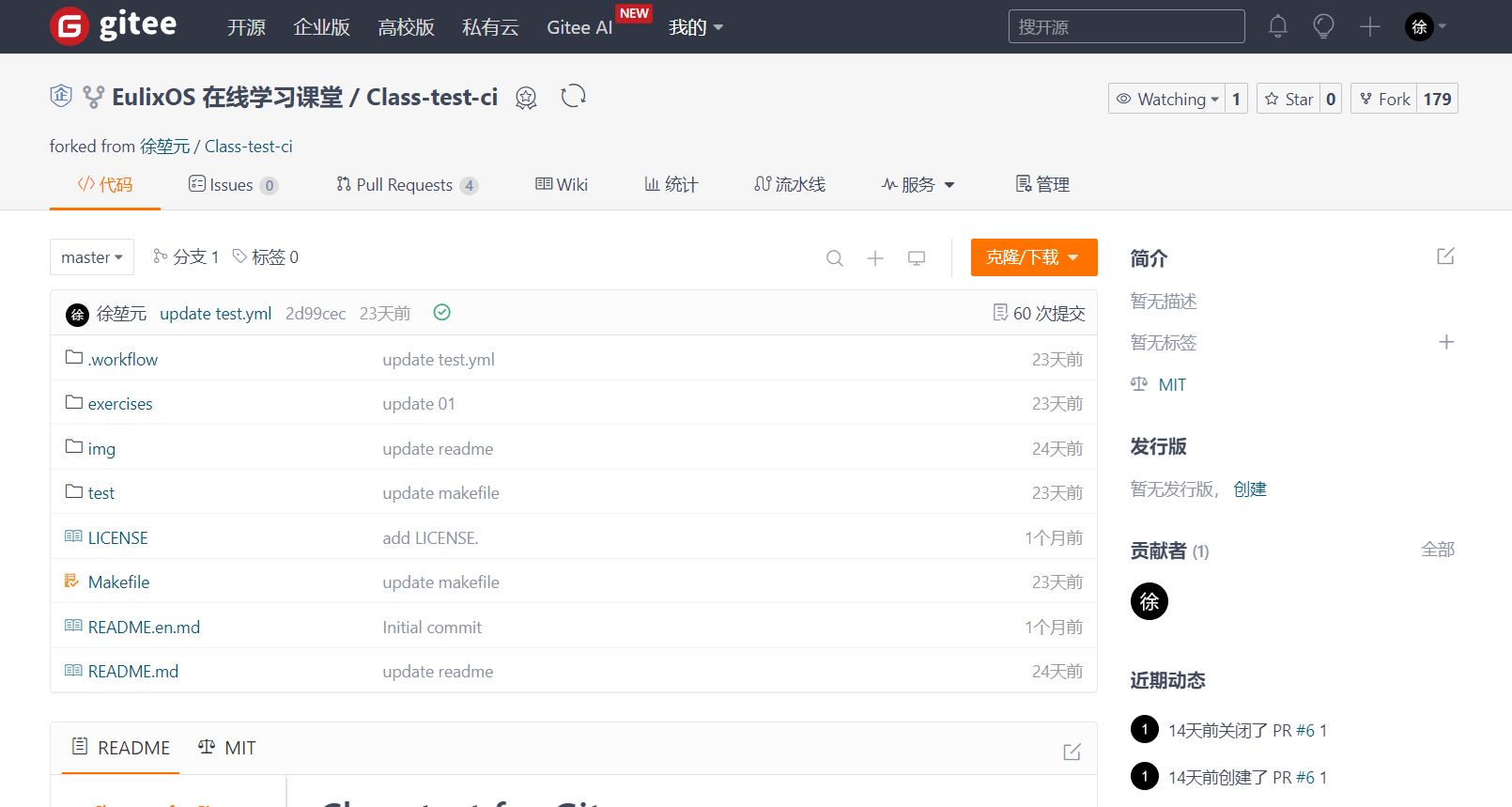
打开某一仓库后的 Gitee 页面如上图所示
1. 注册与登录
访问 Gitee 官网,点击右上角的“注册”按钮进行账号注册。你需要提供邮箱地址、用户名和密码。注册完成后,使用你的用户名和密码登录 Gitee。
2. 创建仓库
登录后,点击页面右上角的“+”号,选择“新建仓库”。在创建仓库页面,填写仓库名称、选择仓库的可见性(公开或私有)、添加仓库描述、选择是否初始化仓库以及是否添加 README、.gitignore 和开源许可证等文件。完成设置后,点击“创建仓库”。
3. 仓库管理
在仓库页面,通过最右侧的“管理”你可以进行多种管理操作:
- 基本信息:编辑仓库的名称、描述、可见性等。
- 分支保护:设置分支保护规则,防止重要分支被错误地修改或删除。
- WebHooks:配置 WebHooks,当仓库发生特定事件(如推送代码)时,自动触发外部服务。
- 部署密钥:添加部署密钥,允许服务器无密码访问仓库。
- 成员管理:邀请其他用户加入仓库,并设置他们的权限级别。
4. 克隆仓库
在仓库页面,找到“克隆/下载”按钮,选择 HTTPS 或 SSH 方式获取仓库的 URL。然后,在本地命令行中使用 git clone 命令将仓库克隆到本地:
git clone https://gitee.com/username/repository.git
5. 提交与推送
在本地仓库进行修改后,使用以下命令将更改提交到 Gitee 仓库:
git add .
git commit -m "Update README"
git push origin master
6. 拉取更新
如果远程仓库有更新,使用 git pull 命令将更新拉取到本地:
git pull origin master
7. 分支管理
在 Gitee 仓库页面,你可以创建、删除和管理分支。在本地,使用以下命令进行分支操作:
git branch feature-x # 创建新分支
git checkout feature-x # 切换到新分支
git merge feature-x # 将 feature-x 分支合并到当前分支
git branch -d feature-x # 删除 feature-x 分支
8. 问题跟踪
在仓库页面,点击“问题”标签,然后点击“新建问题”按钮创建问题。你可以为问题添加标签、指派负责人、设置截止日期等。
9. 代码审查
在仓库页面,点击“合并请求”标签,然后点击“新建合并请求”按钮。选择源分支和目标分支,填写请求信息,然后提交。其他开发者可以审查代码并提供反馈。
10. 持续集成
在仓库页面,点击“流水线”标签,然后点击“新建流水线”按钮。配置流水线,设置触发条件、构建环境、构建脚本等。提交后,流水线将自动执行代码的构建、测试和部署。更详细的介绍会在之后讲解
11. 使用 Gitee Pages
在仓库页面,点击“服务”下的“Gitee Pages”,然后点击“启动”按钮。配置部署分支和目录,提交后,Gitee Pages 将自动部署你的静态网站。
12. 团队协作
在仓库页面,点击“管理”标签,然后选择“仓库成员管理”。你可以邀请其他用户加入仓库,并设置他们的权限,如只读、写入或管理员。
13. 使用 Gitee API
Gitee 提供了 API 文档,你可以通过 API 自动化管理仓库、问题、合并请求等。
14. 安全设置
在仓库页面,点击“管理”标签,然后选择“仓库设置”。你可以设置仓库的访问权限、分支保护规则、部署密钥等,确保仓库安全。
15. 学习资源
Gitee 提供了帮助中心,你可以在那里找到各种教程、指南和最佳实践,帮助你更好地使用 Gitee。
注:Gitee 平台的部分操作需要在完成实名认证后才能进行,请在注册账号后尽快进行实名认证。
Gitee Go 的配置与使用
Gitee Go 是 Gitee 提供的一个持续集成(CI)服务,它允许开发者自动化代码的构建、测试和部署过程。
详细信息可前往 Gitee 帮助中心查看详细文档,本文主要针对训练营实验进行引导
在进行导学阶段实验时,需要进行以下几个步骤的操作
step1-fork 模板仓库
训练营导学阶段实验仓库地址
通过右上角的 fork 按钮进行 fork 本仓库
注:fork 操作需要在实名认证后进行,请确保你的 Gitee 账户已完成实名认证
step2-开通 Gitee Go
在完成第一步后,切换到自己 fork 的仓库,点击“流水线”
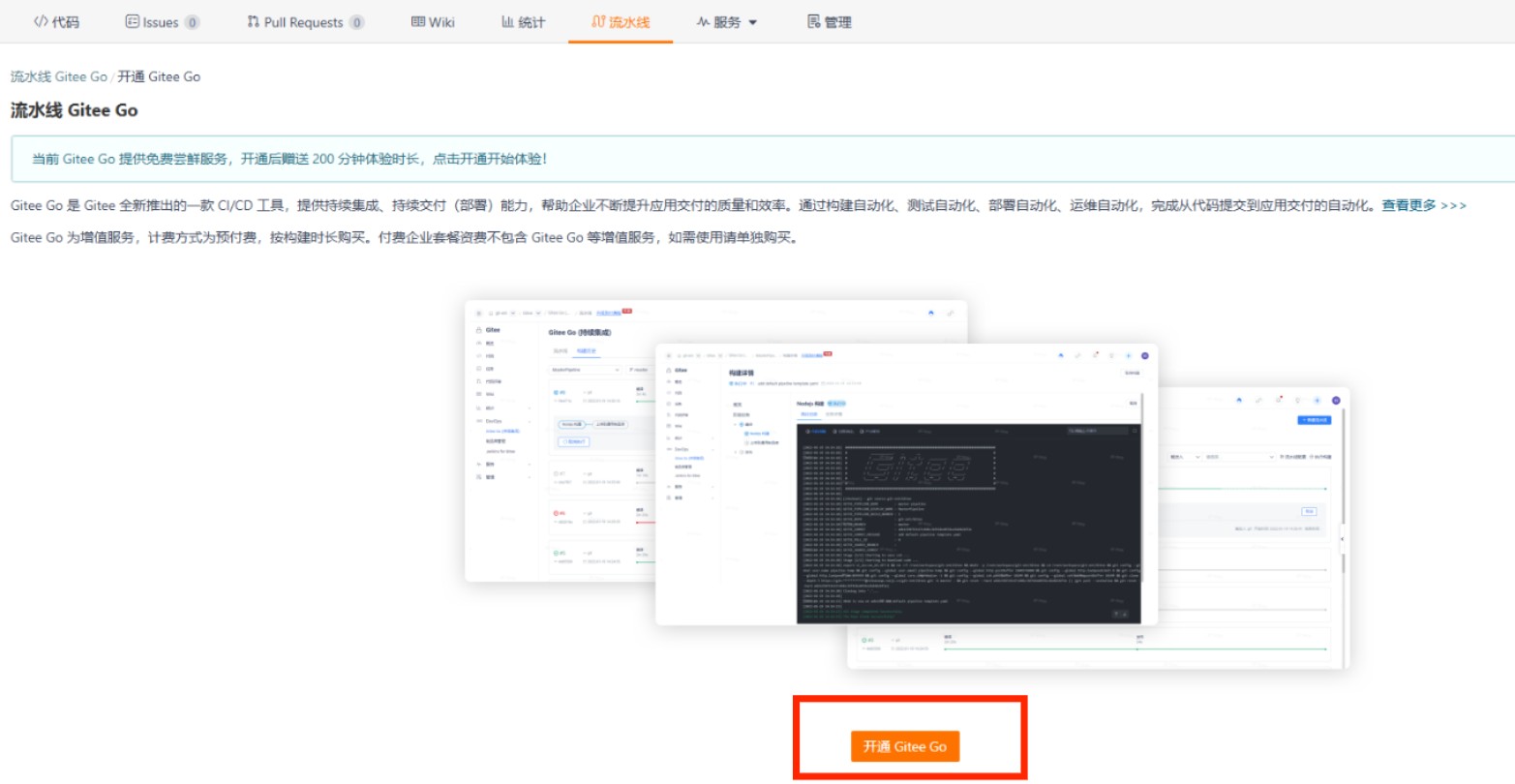
点击”开通 Gitee GO“来使用 CI。
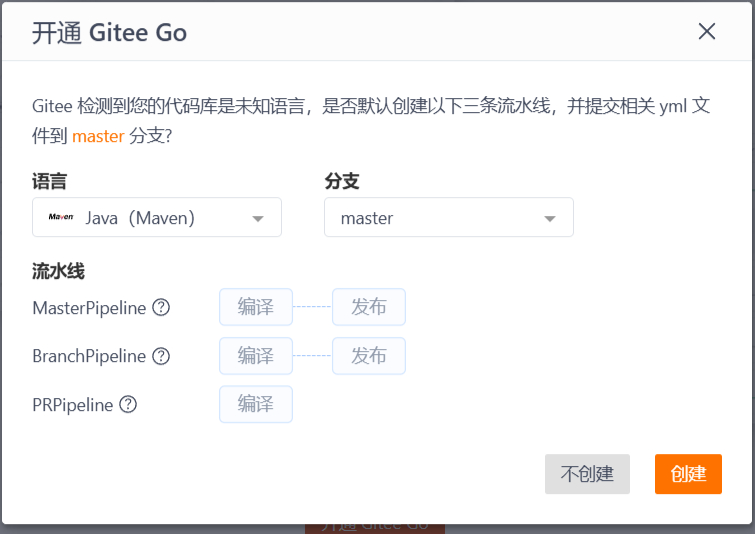
是否创建默认流水线建议选择“不创建”。
注:开通 Gitee go 后流水线页面显示无流水线为正常现象
此后每次向远程仓库的 master 分支进行 push 都会触发流水线进行评测
流水线常见问题与解决方案
在使用 Gitee Go 进行代码托管和自动化测试时,可能会遇到各种问题,如流水线不执行、时间耗尽、运行时间过长等。以下是针对这些常见问题的详细解决方案:
1.在开通 Gitee Go 并向仓库 push 代码后流水线不执行
- 检查流水线时间:首先确认你的仓库流水线时间是否已经耗尽。如果时间耗尽,流水线将不会执行。
- 手动创建流水线:如果流水线时间未耗尽,尝试在流水线页面手动创建新的流水线。使用实验中的流水线配置代码,配置文件通常位于
.workflow/test.yml。 - 修改配置文件:如果手动创建流水线后问题依旧,尝试修改配置文件中的作业名称或阶段名称,然后重新提交。
- 重新 fork 仓库:如果上述步骤都无法解决问题,尝试重新 fork 仓库,然后再次推送代码。
- 手动创建新仓库:如果重新 fork 仓库后问题仍未解决,可以尝试根据当前仓库内容手动创建一个新仓库,但不进行 fork 操作。
2.在开通 Gitee Go 时不小心创建了默认流水线。
- 删除默认流水线:默认流水线的运行不会影响评测流水线的运行,但会消耗时间。你可以在流水线页面手动删除默认流水线。评测流水线的默认名称为“test”。
3.仓库流水线时间耗尽怎么办
- 再 fork 一个仓库:如果仓库的流水线时间耗尽,最简单的解决方案是再 fork 一个仓库,然后继续使用。
4.流水线时间运行过长怎么办
- 手动终止运行:如果流水线运行时间过长,可以手动终止运行。然后查看流水线日志,确定导致运行时间过长的原因。理论上,单次流水线运行时间不应超过半个小时。
5.流水线日志无法生成
- 尝试其他设备或浏览器:如果流水线日志无法生成,尝试使用手机或其他浏览器查看。有时候,问题可能是由于浏览器兼容性或缓存问题导致的。
前置知识
本章介绍完成实验所需的部分前置知识,这些知识在之后的正式实验中也会用到。
Linux 使用入门与配置
Linux 是一个广泛使用的开源操作系统,以其稳定性、安全性和灵活性而闻名。本节将介绍 Linux 的基本使用和配置,帮助读者为后续的实验做好准备。
Linux 简介
Linux 最初由 Linus Torvalds 在1991年开发,它基于 Unix 操作系统。Linux 的核心(Kernel)是操作系统的核心部分,负责管理硬件资源和提供系统服务。Linux 操作系统通常包括核心以及一系列的系统工具、应用软件和图形用户界面(GUI)。
安装 Linux
在开始使用 Linux 之前,首先需要安装一个 Linux 发行版。常见的 Linux 发行版包括 Ubuntu、Fedora、Debian 和 ArchLinux 等。
我们推荐使用 Ubuntu 发行版作为实验环境。
物理机 Linux
- 首先,各位需要根据个人需求和偏好选择一个 Linux 发行版安装,一般来说不同的 Linux 发行版其最明显的区别在于软件包管理器的不同,例如 Debian 系发行版主要采用 apt 进行软件包管理,Arch 发行版则主要采用 pacman 进行软件包管理。
- 确定好自己要使用的发行版之后,一般需要到其官网下载安装镜像。
- 创建启动盘:使用工具如 Rufus 或 Etcher 将 ISO 镜像写入 USB 驱动器或 DVD。
- 启动安装程序:通过启动盘启动计算机,并按照屏幕上的指示进行安装。
新手玩家一般推荐尝试 ArchLinux,如希望尝试 Arch 系发行版可尝试 manjaro
双系统安装
大多数情况下我们不得不使用Windows,那么我们可以考虑在自己的设备上安装 Windows + Linux 双系统。
建议在设备拥有两块可用硬盘的情况下尝试,将两个系统安装在不同的硬盘上
为防止出现错误,请备份数据
双系统安装完成后可能出现系统时间不同步的问题,可参考如下链接解决:
虚拟机/ wsl
如担心直接安装物理机或双系统可能带来的问题,或者担心易用性,可以尝试使用虚拟机或 wsl(Windows 的 Linux 子系统)。
关于 wsl 的安装,请参考如下链接:
Linux 基本命令
文件和目录操作命令
ls:列出目录内容。- 示例:
ls -l以长格式列出当前目录下的所有文件和目录。 - 示例:
ls -a显示所有文件,包括隐藏文件。 - 示例:
ls /home/user列出指定目录/home/user的内容。
- 示例:
cd:改变当前目录。- 示例:
cd /home/user切换到/home/user目录。 - 示例:
cd ..切换到上一级目录。 - 示例:
cd切换到用户的主目录。
- 示例:
pwd:显示当前工作目录的路径。- 示例:
pwd显示当前所在的完整目录路径。
- 示例:
mkdir:创建新目录。- 示例:
mkdir new_directory在当前目录下创建名为new_directory的新目录。 - 示例:
mkdir -p parent/child/grandchild创建多级目录,如果父目录不存在则一并创建。
- 示例:
rm:删除文件或目录。- 示例:
rm file.txt删除名为file.txt的文件。 - 示例:
rm -r directory删除名为directory的目录及其内容。 - 示例:
rm -f file.txt强制删除file.txt文件,不提示确认。
- 示例:
cp:复制文件或目录。- 示例:
cp source.txt destination.txt将source.txt复制为destination.txt。 - 示例:
cp -r source_directory destination_directory复制整个目录及其内容。
- 示例:
mv:移动或重命名文件或目录。- 示例:
mv old.txt new.txt将old.txt重命名为new.txt。 - 示例:
mv file.txt /home/user将file.txt移动到/home/user目录。
- 示例:
文件查看和编辑命令
cat:连接文件并打印到标准输出。- 示例:
cat file.txt显示file.txt的内容。 - 示例:
cat file1.txt file2.txt > combined.txt将file1.txt和file2.txt的内容合并到combined.txt。
- 示例:
more或less:分页查看文件内容。- 示例:
more file.txt逐页显示file.txt的内容。 - 示例:
less file.txt更高级的分页查看,支持向前和向后翻页。
- 示例:
nano或vi:文本编辑器。- 示例:
nano file.txt使用 nano 编辑器打开file.txt。 - 示例:
vi file.txt使用 vi 编辑器打开file.txt。
- 示例:
系统信息和进程管理命令
uname:显示系统信息。- 示例:
uname -a显示所有系统信息,包括内核版本和系统架构。
- 示例:
top:实时显示系统资源使用情况和运行中的进程。- 示例:
top打开 top 命令,查看系统资源和进程信息。
- 示例:
ps:显示当前运行的进程。- 示例:
ps aux显示所有用户的所有进程。
- 示例:
kill:终止进程。- 示例:
kill PID终止指定 PID 的进程。 - 示例:
kill -9 PID强制终止指定 PID 的进程。
- 示例:
网络命令
ping:测试网络连接。- 示例:
ping google.com测试与 google.com 的网络连接。
- 示例:
ifconfig或ip:显示和配置网络接口。- 示例:
ifconfig或ip addr显示所有网络接口的配置信息。
- 示例:
netstat:显示网络连接、路由表和接口统计等。- 示例:
netstat -an显示所有网络连接和端口状态。
- 示例:
通过这些命令,您可以有效地管理文件和目录,查看和编辑文件内容,监控系统资源和进程,以及进行基本的网络配置和故障排查。这些命令是 Linux 系统管理和开发工作的基础。
C 语言基本语法
C语言是一种广泛使用的编程语言,以其效率和灵活性而著称。本节将介绍C语言的基本语法,为后续的实验和开发工作打下基础。
C语言简介
C语言由Dennis Ritchie在1972年开发,最初是为了编写UNIX操作系统而设计的。C语言具有简洁的语法和强大的功能,使其成为系统编程、嵌入式系统和高级应用程序的首选语言。
基本数据类型
C语言的基本数据类型包括整型、浮点型、字符型和布尔型。每种类型都有其特定的内存占用和取值范围。
- 整型:
int通常占用4个字节,但也可以是2个字节,这取决于编译器和系统。short和long可以用来指定不同大小的整数。short int:通常占用2个字节。long int:通常占用4个或8个字节。long long int:通常占用8个字节。
- 浮点型:
float和double分别用于表示单精度和双精度浮点数。float:通常占用4个字节。double:通常占用8个字节。
- 字符型:
char用于存储单个字符,占用1个字节。char:占用1个字节,用于存储字符。
- 布尔型:
_Bool用于存储布尔值(true或false),占用1个字节。_Bool:占用1个字节,用于存储布尔值。
变量和常量
变量是存储数据值的容器,而常量是固定值。
-
变量声明和初始化:
int age = 25; // 声明一个整型变量并初始化为25 float pi = 3.14159; // 声明一个浮点型变量并初始化为3.14159 char letter = 'A'; // 声明一个字符型变量并初始化为'A' -
常量声明:
const int MAX_VALUE = 100; // 声明一个整型常量 const float PI = 3.14159; // 声明一个浮点型常量
运算符
C语言提供了丰富的运算符,用于执行各种操作。
-
算术运算符:
int a = 10, b = 3; int sum = a + b; // 加法 int diff = a - b; // 减法 int product = a * b; // 乘法 float quotient = (float)a / b; // 除法 int remainder = a % b; // 取模 -
关系运算符:
int x = 5, y = 10; if (x == y) { // 等于 printf("x is equal to y\n"); } if (x != y) { // 不等于 printf("x is not equal to y\n"); } if (x > y) { // 大于 printf("x is greater than y\n"); } if (x < y) { // 小于 printf("x is less than y\n"); } if (x >= y) { // 大于等于 printf("x is greater than or equal to y\n"); } if (x <= y) { // 小于等于 printf("x is less than or equal to y\n"); } -
逻辑运算符:
int p = 1, q = 0; if (p && q) { // 逻辑与 printf("Both p and q are true\n"); } if (p || q) { // 逻辑或 printf("Either p or q is true\n"); } if (!p) { // 逻辑非 printf("p is false\n"); } -
位运算符:
int m = 12, n = 5; int and_result = m & n; // 按位与 int or_result = m | n; // 按位或 int xor_result = m ^ n; // 按位异或 int not_result = ~m; // 按位取反 int left_shift = m << 1; // 左移 int right_shift = m >> 1; // 右移
控制结构
控制结构用于控制程序的执行流程。
-
条件语句:
int score = 85; if (score >= 90) { printf("优秀\n"); } else if (score >= 80) { printf("良好\n"); } else if (score >= 70) { printf("中等\n"); } else if (score >= 60) { printf("及格\n"); } else { printf("不及格\n"); } -
循环语句:
// for循环 for (int i = 0; i < 5; i++) { printf("%d\n", i); } // while循环 int j = 0; while (j < 5) { printf("%d\n", j); j++; } // do-while循环 int k = 0; do { printf("%d\n", k); k++; } while (k < 5); -
跳转语句:
// break语句 for (int i = 0; i < 10; i++) { if (i == 5) { break; // 跳出循环 } printf("%d\n", i); } // continue语句 for (int i = 0; i < 10; i++) { if (i == 5) { continue; // 跳过当前循环的剩余部分,进入下一次循环 } printf("%d\n", i); }
函数
函数是C语言中的基本构建块,用于封装可重用的代码。
-
函数定义和调用:
// 函数定义 int add(int a, int b) { return a + b; } // 函数调用 int result = add(3, 4); printf("The result is %d\n", result);
数组和指针
数组用于存储相同类型的多个元素,而指针是存储变量地址的变量。
-
数组操作:
int numbers[5] = {1, 2, 3, 4, 5}; for (int i = 0; i < 5; i++) { printf("%d\n", numbers[i]); } -
指针操作:
int *p; int age = 25; p = &age; // 将age的地址赋给指针p printf("The value of age is %d\n", *p); // 通过指针访问age的值
结构体和联合体
结构体允许用户定义自己的数据类型,它可以将不同类型的数据组合在一起。联合体是一种特殊的结构体,它允许在相同的内存位置存储不同的数据类型。
-
结构体定义和使用:
// 结构体定义 struct Person { char name[50]; int age; }; // 结构体使用 struct Person person1; strcpy(person1.name, "Alice"); person1.age = 30; printf("Name: %s, Age: %d\n", person1.name, person1.age);
make 基本使用与 Makefile
在软件开发中,自动化构建过程是提高效率的关键。make 是一个在类Unix系统中广泛使用的构建自动化工具,它通过读取 Makefile 中的规则来自动化编译和链接程序。本节将介绍 make 的基本使用和 Makefile 的编写。
Makefile 基础
Makefile 是一个文本文件,它包含了一系列规则,每条规则定义了目标文件、依赖文件和生成目标文件的命令。
-
规则格式:
target: dependencies command ...target:通常是需要生成的目标文件。dependencies:生成目标文件所依赖的文件。command:生成目标文件的命令。
基本 Makefile 示例
假设我们有一个简单的C语言项目,包含两个源文件 main.c 和 hello.c,以及一个头文件 hello.h。我们可以创建一个 Makefile 来编译这个项目。
-
Makefile 示例:
# 定义变量 CC = gcc CFLAGS = -Wall -g # 默认目标 all: hello # 目标依赖和命令 hello: main.o hello.o $(CC) $(CFLAGS) -o hello main.o hello.o # 编译规则 main.o: main.c hello.h $(CC) $(CFLAGS) -c main.c hello.o: hello.c hello.h $(CC) $(CFLAGS) -c hello.c # 清理规则 clean: rm -f hello *.o
make 命令的使用
make 命令不仅可以用来编译项目,还可以用来执行 Makefile 中定义的其他任务。
-
指定目标:
make target这里的
target是Makefile中定义的一个目标。如果不指定目标,make会默认执行第一个目标(通常是all)。 -
递归 make: 在大型项目中,可能会有多个子目录,每个子目录都有自己的
Makefile。可以使用make -C命令来递归地调用子目录中的make。make -C subdir -
显示命令: 默认情况下,
make在执行命令时不会显示命令本身,只会显示输出。使用-n或--just-print选项可以只显示命令而不执行。make -n -
忽略错误: 使用
-k或--keep-going选项可以让make在遇到错误时继续执行后续的命令。make -k
Makefile 的高级特性
Makefile 提供了许多高级特性,使得构建过程更加灵活和强大。
-
自动变量:
make提供了一些特殊的自动变量,如$@(目标文件)、$<(第一个依赖文件)和$^(所有依赖文件)。%.o: %.c $(CC) $(CFLAGS) -c $< -o $@ -
伪目标: 伪目标不是真正的文件,而是代表一组操作。例如,
clean通常用来清理编译生成的文件。.PHONY: clean clean: rm -f hello *.o -
内置函数:
make提供了许多内置函数,如wildcard、patsubst、subst等。SRCS := $(wildcard *.c) OBJS := $(patsubst %.c, %.o, $(SRCS)) -
条件语句: 条件语句允许根据不同条件执行不同的命令。
ifeq ($(OS), Windows_NT) RM := del else RM := rm -f endif -
宏定义: 宏定义允许在
Makefile中定义复杂的表达式,并在需要时展开。MACRO = $(CC) $(CFLAGS) -c $< -o $@ %.o: %.c $(MACRO)
如何在非 Linux 环境中完成实验
在软件开发和计算机科学的实验中,Linux 环境因其强大的命令行工具和开源软件的支持而广受欢迎。然而,并非所有开发者或学生都有条件或偏好使用 Linux。本节将探讨如何在非 Linux 环境(如 Windows 或 macOS)中完成实验,确保实验的顺利进行。
使用虚拟机
虚拟机是一种在现有操作系统上模拟完整计算机系统的技术。通过虚拟机,用户可以在非 Linux 系统上运行 Linux 操作系统,从而获得一个隔离的实验环境。
- 安装虚拟机软件:
- 在 Windows 上,可以使用 VMware Workstation 或 VirtualBox。
- 在 macOS 上,可以使用 VMware Fusion 或 Parallels Desktop。
- 创建 Linux 虚拟机:
- 下载 Linux 发行版的 ISO 镜像文件。
- 使用虚拟机软件创建新的虚拟机,并安装 Linux。
- 在虚拟机中进行实验:
- 启动虚拟机,进入 Linux 环境。
- 安装所需的开发工具和软件包。
- 进行实验,所有的操作和数据都将在虚拟机内部进行,不会影响宿主机的环境。
使用容器技术
容器技术如 Docker 提供了一种轻量级的虚拟化方法,允许用户在非 Linux 环境中运行 Linux 容器。容器共享宿主机的操作系统内核,因此启动更快,资源消耗更少。
- 安装 Docker:
- 在 Windows 和 macOS 上,可以从 Docker 官网下载 Docker Desktop。
- 拉取 Linux 容器镜像:
- 使用 Docker 命令从 Docker Hub 拉取所需的 Linux 容器镜像。
- 运行容器进行实验:
- 使用 Docker 命令启动容器,并在容器中进行实验。
- 容器内的操作和数据与宿主机隔离,确保实验环境的一致性和可重复性。
使用 WSL(适用于 Windows)
Windows Subsystem for Linux(WSL)是 Windows 10 的一个功能,允许用户在 Windows 上运行原生的 Linux 二进制文件。WSL 提供了一个兼容 Linux 的子系统,使得在 Windows 上进行 Linux 开发变得更加容易。
- 启用 WSL:
- 在 Windows 上,通过 PowerShell 以管理员身份运行
wsl --install命令来启用 WSL。
- 在 Windows 上,通过 PowerShell 以管理员身份运行
- 安装 Linux 发行版:
- 从 Microsoft Store 安装所需的 Linux 发行版,如 Ubuntu。
- 在 WSL 中进行实验:
- 启动 Linux 发行版,进行实验。
- WSL 提供了一个完整的 Linux 环境,可以运行大多数 Linux 命令和应用程序。
使用跨平台工具和框架
许多现代的开发工具和框架都是跨平台的,可以在 Windows、macOS 和 Linux 上运行。选择这些工具可以减少环境配置的复杂性。
- 选择跨平台工具:
- 例如,使用跨平台的 IDE(如 Visual Studio Code)和构建工具(如 CMake 或 Gradle)。
- 配置环境变量:
- 确保所有必要的工具和库都已安装,并正确配置环境变量。
- 进行实验:
- 在非 Linux 环境中使用跨平台工具进行实验,确保实验结果的可移植性。
开始实验
本章我们将正式开始进行实验。
实验代码框架讲解
项目结构
.
├── exercises //所有习题都在此文件夹下
├── LICENSE
├── Makefile
├── README.en.md
├── README.md
└── test //所有测例都在此文件夹下
- exercises:这个文件夹包含了所有的习题代码。每个习题可以作为一个子文件夹,其中包含习题的源代码、数据文件和任何相关的资源。
- LICENSE:项目的许可证文件,定义了项目的使用、修改和分发的法律条款。
- Makefile:一个自动化构建脚本,用于编译、测试和清理项目。通过运行
make命令,可以执行 Makefile 中定义的任务。 - test:这个文件夹包含了所有的测试用例。每个测试用例可以作为一个子文件夹或文件,用于验证习题代码的正确性。
Makefile 内容
实验框架的 Makefile:
# Makefile for C language exercise project
# Define the directory where the exercise files are stored
EXERCISE_DIR = ./exercises
# Define the test directory
TEST_DIR = ./test
# Define the build directory
BUILD_DIR = ./build
# Ensure the test and build directories exist
$(shell mkdir -p $(TEST_DIR) $(BUILD_DIR))
# Define the list of exercises
EXERCISES = $(wildcard $(EXERCISE_DIR)/*.c)
# Define the list of executables
EXECUTABLES = $(patsubst $(EXERCISE_DIR)/%.c, $(BUILD_DIR)/%, $(EXERCISES))
# Define compiler and linker flags
CC = gcc
CFLAGS = -Wall -Wextra -std=c99
LDFLAGS = -lm
# Default target: build all executables
all: $(EXECUTABLES) clean
# Build rule for each executable
$(BUILD_DIR)/%: $(EXERCISE_DIR)/%.c
$(CC) -o $@ $< $(CFLAGS) $(LDFLAGS)
# Clean rule to remove all executables and object files
clean:
rm -f $(EXECUTABLES) $(BUILD_DIR)/*.o
# Generate test cases rule
generate-test-cases: $(EXECUTABLES)
@for exe in $(EXECUTABLES); do \
./$$exe > $(TEST_DIR)/$$(basename $$exe).out; \
done
@$(MAKE) clean
# Test rule to compare output with expected results
test-output: $(EXECUTABLES)
@for exe in $(EXECUTABLES); do \
exercise_name=$$(basename $$exe); \
expected=$$(cat $(TEST_DIR)/$${exercise_name}.out); \
actual=$$($$exe); \
if [ "$$expected" = "$$actual" ]; then \
echo "Test for $${exercise_name} passed."; \
else \
echo "Test for $${exercise_name} failed."; \
echo "Expected:"; echo "$$expected"; \
echo "Actual:"; echo "$$actual"; \
fi; \
done
@$(MAKE) clean
# New target to save test results and count pass rate in JSON format
save-test-results: $(EXECUTABLES)
@total=0; \
passed=0; \
> $(BUILD_DIR)/test_results.json; \
for exe in $(EXECUTABLES); do \
exercise_name=$$(basename $$exe); \
expected=$$(cat $(TEST_DIR)/$${exercise_name}.out); \
actual=$$($$exe); \
total=$$((total+1)); \
if [ "$$expected" = "$$actual" ]; then \
passed=$$((passed+1)); \
fi; \
done; \
echo "{\"channel\": \"gitee\",\"courseId\": 1558,\"ext\": \"aaa\",\"name\": \"\",\"score\": $$passed,\"totalScore\": 5}" > $(BUILD_DIR)/test_results.json
@$(MAKE) clean
.PHONY: all clean generate-test-cases test-output save-test-results
- 目录定义:
EXERCISE_DIR:存放练习文件的目录。TEST_DIR:存放测试文件的目录。BUILD_DIR:存放构建产物的目录。
- 文件和目录操作:
mkdir -p $(TEST_DIR) $(BUILD_DIR):确保测试和构建目录存在。
- 编译和链接:
CC = gcc:定义编译器为gcc。CFLAGS = -Wall -Wextra -std=c99:编译选项,包括警告和C99标准。LDFLAGS = -lm:链接选项,链接数学库。
- 构建规则:
$(BUILD_DIR)/%: $(EXERCISE_DIR)/%.c:为每个练习文件生成对应的执行文件。
- 清理规则:
clean:删除所有执行文件和构建目录下的对象文件。
- 测试规则:
generate-test-cases:生成测试用例。test-output:运行测试并比较输出结果。save-test-results:保存测试结果和通过率到JSON文件。
使用 makefile 进行实验
在实验过程中,Makefile提供了自动化构建和测试的便利。以下是如何使用这个Makefile进行实验的步骤:
-
编译所有练习:
make这个命令会编译所有练习文件,并在
BUILD_DIR目录下生成对应的执行文件。 -
生成测试用例:
make generate-test-cases这个命令会运行所有执行文件,并将输出保存为测试用例。
-
运行测试:
make test-output这个命令会比较每个执行文件的输出与预期结果,并显示测试结果。
-
保存测试结果:
make save-test-results这个命令会计算测试的通过率,并将结果保存到
test_results.json文件中。 -
清理:
make clean这个命令会删除所有构建产物和对象文件,保持环境整洁。
本地测试流程
在实验过程中,本地测试是验证代码正确性的关键步骤。以下是本地测试的具体流程:
-
运行所有题目的测试:
make test-output这个命令会执行所有题目的测试,并输出测试结果。确保你的代码在提交之前通过了所有本地测试。
-
测试并保存结果:
mkdir build make save-test-results这个命令会创建一个名为
build的目录,并在该目录下生成一个test_results.json文件,用于保存测试结果。这个文件对于记录和跟踪实验进度非常有用。
测试结果文件格式
test_results.json 文件的格式如下:
{
"channel": "gitee", // 提交渠道
"courseId": 1558, // 课程ID
"ext": "aaa",
"name": "xukunyuan-star", // 提交者信息
"score": 5, // 提交者当前分数
"totalScore": 5 // 当前实验总分
}
这个文件包含了提交渠道、课程ID、扩展信息、提交者名称、当前分数以及实验总分等关键信息。确保每次测试后都更新这个文件,以便于跟踪实验的进度和成绩。
注意,在本地测试的过程中,请注意不要破坏测例
实验相关资料汇总
导学阶段的实验相对简单,以下是一部分实验相关资料的汇总:
make 与 Makefile 教程
阮一峰的这篇博客详细介绍了make命令及其配置文件Makefile的使用。make是一个构建自动化工具,它根据Makefile中的规则来编译和链接程序。这篇文章适合那些希望提高项目构建效率的开发者。
这本书籍风格的教程深入浅出地讲解了如何编写Makefile。它从基础规则到高级技巧,逐步引导读者掌握Makefile的编写,适合希望深入理解make工具的读者。
C语言教程
菜鸟教程提供了全面的C语言学习资源,从基础语法到高级特性,适合初学者和希望复习C语言的开发者。这个教程的特点是实例丰富,易于理解。
Linux 教程
菜鸟教程的Linux部分覆盖了从Linux基础命令到系统管理的各个方面。这个教程适合希望快速入门Linux操作系统的用户。
这是一个个人笔记式的Linux教程,内容详实,适合有一定基础并希望深入学习Linux系统的用户。
鼎鼎大名的 PA 实验的开头章节,很适合用于 Linux 使用的上手。
算法与数据结构
菜鸟教程的数据结构与算法部分提供了基础的数据结构和算法知识,适合初学者学习。
这是一个GitHub上的算法教程项目,包含了多种算法的实现和解释,适合希望提高算法能力的开发者。
第一题:输出 Hello World!
实验题目
补全代码框架,向控制台打印“Hello World!”
实验要求
- 编写一个C程序:使用C语言编写一个简单的程序。
- 打印输出:在控制台(或命令行界面)上打印出“Hello, World!”这条消息。
实验代码框架
//01_helloworld.c
#include <stdio.h>
int main(){
// Print "Hello World!" to the console
return 0;
}
实验解析
代码实现
#include <stdio.h>
int main() {
// 打印 "Hello, World!" 到控制台
printf("Hello, World!\n");
return 0;
}
代码解释
#include <stdio.h>:这是一个预处理指令,用于包含标准输入输出头文件stdio.h。这个头文件包含了printf函数的声明,printf函数用于在控制台上输出文本。int main():这是C程序的主函数,程序从这里开始执行。int表示这个函数返回一个整数值。printf("Hello, World!\n");:这是一个函数调用,printf是C标准库中的一个函数,用于格式化输出。在这个例子中,它被用来输出字符串“Hello, World!”。\n是一个转义字符,表示换行,使得下一次输出从新的一行开始。return 0;:这是main函数的返回语句。在C语言中,main函数返回0通常表示程序正常结束。
第二题:基本循环
实验题目
编写一个C程序,打印出从1到10的整数序列。
使用循环实现迭代,并且每次迭代结束后,通过标准输出打印当前的计数值,每个数值打印在新的一行上。
实验要求
- 循环结构:使用循环(如
for循环、while循环或do-while循环)来实现迭代。 - 打印输出:每次迭代结束后,通过标准输出(通常是终端或命令行界面)打印当前的计数值。
- 格式要求:每个数值打印在新的一行上。
实验代码框架
//02_loop.c
#include <stdio.h>
/**
* 编写一个C程序,打印出从1到10的整数序列。
* 使用循环实现迭代,并且每次迭代结束后,通过标准输出打印当前的计数值,每个数值打印在新的一行上。
*/
int main(void)
{
//TODO
return 0;
}
实验解析
代码实现
使用for循环实现
#include <stdio.h>
int main(void)
{
// 使用for循环打印1到10的整数
for (int i = 1; i <= 10; i++) {
printf("%d\n", i);
}
return 0;
}
使用while循环实现
#include <stdio.h>
int main(void)
{
int i = 1;
// 使用while循环打印1到10的整数
while (i <= 10) {
printf("%d\n", i);
i++;
}
return 0;
}
使用do-while循环实现
#include <stdio.h>
int main(void)
{
int i = 1;
// 使用do-while循环打印1到10的整数
do {
printf("%d\n", i);
i++;
} while (i <= 10);
return 0;
}
第三题:打印九九乘法表
实验题目
编写一个C程序,打印出9x9乘法表的一部分。
程序应该使用两个嵌套的 for 循环来实现。外层循环控制乘法表的行数,从1到9;内层循环控制每行中的列数,列数应该等于当前的行数。
在每个内层循环中,程序应该打印出当前列数和行数的乘积,并且每个乘积后面跟随一个制表符 \t 以保持格式整齐。
每行结束后,程序应该打印一个换行符 \n 以开始新的一行。
参考输出格式 printf("%d*%d=%d\t", j, i, i * j);
实验要求
- 使用嵌套循环:程序需要使用两个嵌套的
for循环来实现乘法表的打印。 - 外层循环:外层循环控制乘法表的行数,从1到9。
- 内层循环:内层循环控制每行中的列数,列数应该等于当前的行数。
- 打印乘积:在每个内层循环中,程序应该打印出当前列数和行数的乘积,并且每个乘积后面跟随一个制表符
\t以保持格式整齐。 - 换行:每行结束后,程序应该打印一个换行符
\n以开始新的一行。
实验代码框架
//03_nested_loops.c
#include <stdio.h>
/**
* 题目描述:
* 编写一个C程序,打印出9x9乘法表的一部分。
* 程序应该使用两个嵌套的 for 循环来实现。外层循环控制乘法表的行数,从1到9;内层循环控制每行中的列数,列数应该等于当前的行数。
* 在每个内层循环中,程序应该打印出当前列数和行数的乘积,并且每个乘积后面跟随一个制表符 \t 以保持格式整齐。
* 每行结束后,程序应该打印一个换行符 \n 以开始新的一行。
* 参考输出格式 printf("%d*%d=%d\t", j, i, i * j);
*/
int main(void)
{
//TODO
return 0;
}
实验解析
代码实现
#include <stdio.h>
int main(void)
{
// 外层循环控制行数
for (int i = 1; i <= 9; i++) {
// 内层循环控制列数,列数等于当前行数
for (int j = 1; j <= i; j++) {
// 打印乘积和制表符
printf("%d*%d=%d\t", j, i, i * j);
}
// 每行结束打印换行符
printf("\n");
}
return 0;
}
代码解释
- 外层循环:
for (int i = 1; i <= 9; i++),这个循环从1到9,代表乘法表的行数。 - 内层循环:
for (int j = 1; j <= i; j++),这个循环的次数由外层循环的当前值i决定,即每行的列数等于当前的行数。 - 打印乘积:
printf("%d*%d=%d\t", j, i, i * j);,这个语句打印出当前列数j和行数i的乘积,并且每个乘积后面跟随一个制表符\t,以保持输出格式整齐。 - 换行:
printf("\n");,这个语句在每行结束后打印一个换行符\n,以开始新的一行。
第四题:求素数
实验题目
查找100以内的最大素数
实验要求
- 查找素数:程序需要查找100以内的所有素数。
- 找到最大素数:在找到的所有素数中,确定最大的一个。
实验代码框架
// 04_prime_number.c
#include <stdio.h>
#include <math.h>
//查找100以内的最大素数
int main(void)
{
int i, j;
int max = 0;
for (i = 1; i <= 100; i++)
{
//TODO
}
printf("max = %d\n", max);
return 0;
}
实验解析
代码实现
#include <stdio.h>
#include <math.h>
int main(void)
{
int i, j;
int max = 0;
for (i = 1; i <= 100; i++)
{
// 检查i是否为素数
int isPrime = 1; // 假设i是素数
for (j = 2; j <= sqrt(i); j++)
{
if (i % j == 0)
{
isPrime = 0; // i不是素数
break;
}
}
// 如果i是素数且大于当前的最大素数,更新max
if (isPrime && i > max)
{
max = i;
}
}
printf("max = %d\n", max);
return 0;
}
代码解释
- 外层循环:
for (i = 1; i <= 100; i++),这个循环遍历1到100之间的所有数字。 - 内层循环:
for (j = 2; j <= sqrt(i); j++),这个循环用于检查当前的i是否为素数。内层循环从2开始,到sqrt(i)结束,因为一个数如果可以被小于或等于其平方根的数整除,那么它就不是素数。 - 检查素数:
if (i % j == 0),如果i能被j整除,则i不是素数,将isPrime设置为0,并跳出内层循环。 - 更新最大素数:
if (isPrime && i > max),如果i是素数且大于当前的最大素数max,则更新max为i。 - 输出结果:
printf("max = %d\n", max);,循环结束后,打印出找到的最大素数。
第五题:约瑟夫环
实验题目
给定100个人站成一圈,从第1个人开始依次报数。
每数到3的人将会被淘汰,然后继续从下一个人开始报数。
这个过程会一直持续,直到所有的人都被淘汰。
请编写一个C语言程序来模拟这个过程,并且输出每一个被淘汰人的编号。
要求:输出每一个被淘汰人的编号,每淘汰一个人输出一行,格式为:"%d out \n"(每输出一次换行)
实验要求
- 模拟约瑟夫环:程序需要模拟100个人围成一圈,从第1个人开始报数,每数到3的人被淘汰的过程。
- 输出淘汰顺序:程序需要输出每一个被淘汰人的编号,每淘汰一个人输出一行,格式为:
"%d out \n"。
实验代码框架
// 05_josephus_ring.c
#include <stdio.h>
/**
* 给定100个人站成一圈,从第1个人开始依次报数。
* 每数到3的人将会被淘汰,然后继续从下一个人开始报数。
* 这个过程会一直持续,直到所有的人都被淘汰。
* 请编写一个C语言程序来模拟这个过程,并且输出每一个被淘汰人的编号。
* 要求:输出每一个被淘汰人的编号,每淘汰一个人输出一行,格式为:"%d out \n"(每输出一次换行)
*/
#define ALL_NUM 100
#define COUNT_NUM 3
#define OUT_NUM 3
/* people id array such as (1,2,3,4,5,6) */
int people[ALL_NUM];
int main(void)
{
int left; /* 剩余人数 */
int pos; /* 当前报数位置 */
int step; /* 当前报数 */
//TODO
return 0;
}
实验解析
代码实现
#include <stdio.h>
#define ALL_NUM 100 // 总人数
#define COUNT_NUM 3 // 报数到3的人被淘汰
#define OUT_NUM 3 // 淘汰的数字
int people[ALL_NUM]; // 人员编号数组
int main(void)
{
int left = ALL_NUM; // 剩余人数
int pos = 0; // 当前报数位置
int step = 0; // 当前报数
while (left > 0)
{
// 模拟报数
step++;
if (step == COUNT_NUM)
{
// 输出被淘汰的人的编号
printf("%d out\n", people[pos] + 1);
// 淘汰这个人
for (int i = pos; i < left - 1; i++)
{
people[i] = people[i + 1];
}
left--;
step = 0; // 重置报数
}
// 移动到下一个人
pos = (pos + 1) % left;
}
return 0;
}
代码解释
- 初始化:定义了总人数
ALL_NUM,淘汰数字COUNT_NUM,以及一个数组people来存储每个人的编号。 - 模拟报数:使用一个循环来模拟报数过程,直到所有人都被淘汰。
- 报数和淘汰:
step变量用于记录当前报数,当step等于COUNT_NUM时,表示当前报数的人应该被淘汰。此时,输出该人的编号,并从数组中移除这个人,然后重置step。 - 移动到下一个人:使用
pos = (pos + 1) % left来移动到下一个人,这里使用了取模运算来保证在数组长度变化时,pos始终指向有效的位置。
导学阶段实验相关问题与解决方案
在导学阶段的实验中,学生们可能会遇到各种问题,这些问题可能涉及代码实现、测试案例管理以及实验顺序等方面。以下是对这些常见问题的详细解答和建议解决方案:
1.我按照题目的要求完成了代码,但是并没有通过测试
当你发现自己的代码没有通过测试时,首先应该回顾题目描述,特别是关于输出格式的部分。确保你的程序输出严格遵循了题目要求的格式。例如,如果题目要求输出结果时每行一个数字,并且每个数字后面跟着一个空格,那么你的程序输出也应该如此。如果输出格式不正确,即使算法逻辑正确,也可能导致测试失败。因此,仔细检查并调整输出格式是解决此类问题的第一步。
2.我不小心破坏了测例怎么办
在实验过程中,如果你不小心修改或删除了测试案例,不必过于担心。你可以选择以下两种方法之一来恢复测试案例:
- 重新从模板仓库 fork:如果你之前是从一个模板仓库 fork 出来的,你可以再次 fork 一个新的仓库,这样你将获得一个包含完整测试案例的新副本。
- 直接获取测例:如果模板仓库提供了测试案例的下载,你可以直接下载最新的测试案例文件,并将其添加到你的项目中。
这两种方法都可以帮助你快速恢复测试环境,继续进行实验。
3.是否可以不按照习题文件的顺序完成习题
答案是肯定的。虽然习题文件可能按照一定的逻辑顺序排列,但这并不意味着你必须严格按照这个顺序来完成习题。你可以根据自己的学习进度和理解程度,选择先完成你认为更重要的或者更感兴趣的习题。这种灵活性可以帮助你更好地掌握知识点,并根据自己的学习节奏进行调整。
提交成绩
经过上一章的学习与讲解,相信大家都已经顺利完成了实验,本章将会引导大家提交实验的成绩。
流水线测试过程
流水线配置
version: '1.0'
name: test
displayName: test
triggers:
trigger: auto
push:
branches:
prefix:
- ''
variables:
POST_API: ***
stages:
- name: build-test
displayName: build-test
strategy: naturally
trigger: auto
executor: []
steps:
- step: build@gcc
name: build_gcc
displayName: build
gccVersion: '9.4'
commands:
- apt-get update
- ''
- apt-get install -y curl
- ''
- mkdir build
- ''
- make test-output
- ''
- make save-test-results
- ''
- gitee_id="$GITEE_PIPELINE_TRIGGER_USER"
- ''
- json_file="build/test_results.json"
- ''
- existing_json=$(cat "$json_file")
- ''
- updated_json=$(echo "$existing_json" | jq --arg gitee_id "$gitee_id" '.name = $gitee_id')
- ''
- echo "$updated_json" > "$json_file"
- ''
- cat build/test_results.json
- ''
- 'curl -X POST "$POST_API" -H "accept: application/json;charset=utf-8" -H "Content-Type: application/json" -d "$(cat build/test_results.json)" -v'
- ''
- ''
artifacts:
- name: test_results
path:
- ./build/test_results.json
caches: []
notify: []
strategy:
retry: '0'
流水线的配置文件定义了一个名为“test”的流水线,它具有自动触发的特性。该流水线包含一个阶段(stage),名为“build-test”,其目的是构建和测试代码。
其包含以下几个步骤:
环境准备
在“build-test”阶段中,首先执行的是环境准备步骤。这包括更新包列表(apt-get update)和安装必要的软件(apt-get install -y curl)。这些步骤确保了构建和测试环境的一致性和可用性。
构建与测试
接下来,流水线创建一个名为“build”的目录,并在其中执行构建命令(make test-output)和保存测试结果的命令(make save-test-results)。这些命令是构建和测试过程的核心。
结果处理
测试完成后,流水线会读取build/test_results.json文件中的测试结果,并使用jq工具更新其中的giteeName字段。这一步骤确保了测试结果中包含了执行流水线的用户的Gitee ID。
结果提交
更新后的测试结果通过curl命令被发送到指定的API($POST_API)。这一步骤实现了测试结果的自动化提交,使得测试结果可以被远程服务器接收和处理。
结果归档
最后,流水线将build/test_results.json文件作为构建产物(artifact)归档,以便后续的分析和审查。
如何进行流水线测试
完成实验后,请上传至远程仓库运行 CI。详细执行情况与输出可在流水线页面查看。
排行榜成绩查看与绑定
导学阶段排行榜地址
为了方便参与者查看自己的成绩和排名,训练营提供了一个专门的排行榜页面。你可以通过以下链接访问导学阶段的晋级榜单:
在通过在线的 CI 评测后,你的成绩会被发送到训练营的排行榜上。
排行榜信息展示
当你访问排行榜页面时,你会看到一个包含多个列的表格,其中详细列出了每位参与者的相关信息:
- 排名:显示你在所有参与者中的相对位置。
- 姓名(昵称):显示你的姓名或昵称,用于标识个人。
- 分数:显示你通过在线 CI 评测获得的成绩。
- 最后提交时间:显示你最近一次提交代码的时间。
这些信息帮助你了解自己在训练营中的表现,并与他人进行比较。
成绩绑定的重要性
为了确保你的成绩能够正确地显示在排行榜上,并在训练营中得到认可,你需要在训练营网站上正确填写你的 GitHubName 或 GiteeName。这些信息用于将你的提交与你的个人账户关联起来。如果这些信息填写不正确或不完整,可能会导致成绩无法正确绑定,从而影响你的排名和晋级机会。
操作步骤
- 访问个人信息页面:登录训练营网站,找到并访问个人信息页面。
- 填写 GitHubName/GiteeName:在个人信息页面中,找到相关的字段,填写你的 GitHubName 或 GiteeName。确保信息的准确性。
- 保存更改:填写完毕后,保存你的更改。
- 提交代码:在完成代码编写并通过本地测试后,提交你的代码到训练营的评测系统。
- 查看排行榜:提交后,访问排行榜页面,查看你的成绩和排名是否正确显示。
通过遵循这些步骤,你可以确保你的成绩被正确地绑定到排行榜上,从而在训练营中获得公正的评价和机会。如果有任何疑问或遇到问题,不要犹豫,及时联系训练营的技术支持团队寻求帮助。
如何晋级
晋级要求
在导学阶段,我们鼓励每位学员积极参与,但并没有设定强制性的晋级要求。为了确保学员能够顺利过渡到正式阶段,我们建议学员在进入正式阶段之前,完成基础阶段的实验与课程。这不仅有助于巩固基础知识,也为后续的实验和项目打下坚实的基础。
晋级依据
晋级的依据主要基于训练营教学系统排行榜上显示的分数。与正式阶段不同,导学阶段并不强制要求达到特定的分数。只要学员报名参加了训练营,并积极参与了导学阶段的学习,就有资格晋级到正式阶段。
晋级过程
为了顺利进行后续的学习和交流,晋级过程中需要加入对应的微信群聊。学员可以通过联系训练营的班主任或管理人员来加入这些群聊。具体的加群方式和相关信息,可以在训练营教学系统中找到。
队伍晋级
对于组队学习的学员,队伍晋级是一个重要的环节。为了确保队伍的有效性,全队所有学员都必须完成个人晋级。只有当队伍中的所有成员都成功晋级后,整个队伍才能晋级。值得注意的是,队伍晋级并不影响个人晋级,这意味着即使队伍未能晋级,个人仍然有机会根据个人表现晋级。
为了保证队伍的有效性,我们规定两人及两人以上的队伍才能被视为有效组队。这有助于确保团队合作的质量,并鼓励学员之间的交流与协作。
提交过程相关问题与解决方案
1.晋级榜单上的成绩没有准确链接到用户信息
如果你发现晋级榜单上的成绩没有正确链接到你的用户信息,首先应该检查你的个人信息页面。确保你已经正确填写了你的 GitHubName 或 GiteeName。这些信息是用来关联你的成绩和你的账户的。如果信息填写正确,但问题依旧存在,尝试重新提交你的代码。这通常可以刷新成绩和用户信息的链接。如果问题仍然没有解决,可以联系技术支持寻求帮助。
2.本地代码无法提交到远程仓库
当你遇到本地代码无法提交到远程仓库的问题时,首先应该检查你的网络连接是否正常。网络问题是导致提交失败的常见原因。如果网络没有问题,建议使用 SSH 协议进行提交,因为 SSH 通常比 HTTPS 更稳定,尤其是在处理大量数据时。如果使用 SSH 后问题依旧,那么可能是由于内容冲突导致的。内容冲突通常发生在多人在同一分支上工作时。解决冲突的方法是手动合并代码,确保每个更改都被正确地包含在提交中。
3.使用 wsl 进行实验,但因 wsl 网络问题无法提交
如果你在使用 Windows Subsystem for Linux (WSL) 进行实验时遇到网络问题,导致无法提交代码,可以尝试以下解决方案:
- 复制仓库到 Windows 文件系统:将你的本地仓库从 WSL 复制到 Windows 文件系统中,然后使用 Git 客户端进行提交。这种方法可以绕过 WSL 的网络限制,因为 Windows 文件系统通常有更好的网络兼容性。
- 检查 WSL 网络设置:确保 WSL 的网络设置正确,包括防火墙设置和网络配置。有时候,简单的网络设置调整就可以解决问题。
晋级之后
经过之前的学习,相信大家已经完成了导学阶段的学习与晋级要求,本章将引导大家在下一阶段正式开始之前的余下时间可以拓展的内容,以及对后续学习的引导。
拓展内容与学习资源汇总
本节内容持续更新
导学课程相关学习资料
导学阶段课程课件
riscv-operating-system-mooc/slides
此链接包含导学阶段课程《循序渐进,学习开发一个 RISC-V 上的操作系统 的全部课件,可作为视频课程的辅助之用。
课程配套实验
此链接为导学阶段课程的配套实验代码仓库,实验难度不大,适合初学者了解系统编程与操作系统理论知识,推荐尝试。
一个可运行课程实验的 RISCV CPU
此仓库为一位该课程《循序渐进,学习开发一个 RISC-V 上的操作系统 》 的热心学员设计的 RISCV CPU,可在其上运行课程配套的实验代码。
课程代码到物理机的移植记录
riscv-operating-system-mooc/issues/I64EEQ
这里记录了该课程配套代码向物理机的移植记录,鼓励大家在完成本课程后积极参与这一活动,提高自己的系统编程与工程能力。
一份来自b站本课程学员的学习笔记
RISC-V入门(基础概念+汇编部分) 基于 汪辰老师的视频笔记
其余学习资料
uCore 实验指导书
uCore 实验同样为实现一个 RISCV 架构操作系统的教学用操作系统,其难度较于导学阶段课程颇高,但是内容完善,体系严整,可作为完成课程后的提高之用。
rCore 实验指导书
rCore 实验与 uCore 实验内容基本相同,但是 rCore 代码框架使用 Rust 语言编写,欲进行实验需要先行学习 Rust,但通过本实验可以学习 Rust base OS 这一新兴技术,建议学有余力的学员进行尝试。
清华大学操作系统课程资料
此链接整合了清华大学计算机系2024春季学习操作系统课程课堂幻灯片的主要内容,对幻灯片中的一些概念进行了简单补充。
南京大学计算机系统基础实验(PA)
南京大学 计算机科学与技术系 计算机系统基础课程实验 2024
南京大学操作系统课程
静态程序分析
有趣的 Git 学习平台
make 与 Makefile 教程
阮一峰的这篇博客详细介绍了make命令及其配置文件Makefile的使用。make是一个构建自动化工具,它根据Makefile中的规则来编译和链接程序。这篇文章适合那些希望提高项目构建效率的开发者。
这本书籍风格的教程深入浅出地讲解了如何编写Makefile。它从基础规则到高级技巧,逐步引导读者掌握Makefile的编写,适合希望深入理解make工具的读者。
C语言教程
菜鸟教程提供了全面的C语言学习资源,从基础语法到高级特性,适合初学者和希望复习C语言的开发者。这个教程的特点是实例丰富,易于理解。
Linux 教程
菜鸟教程的Linux部分覆盖了从Linux基础命令到系统管理的各个方面。这个教程适合希望快速入门Linux操作系统的用户。
这是一个个人笔记式的Linux教程,内容详实,适合有一定基础并希望深入学习Linux系统的用户。
鼎鼎大名的 PA 实验的开头章节,很适合用于 Linux 使用的上手。
The Missing Semester of Your CS Education
算法与数据结构
菜鸟教程的数据结构与算法部分提供了基础的数据结构和算法知识,适合初学者学习。
这是一个GitHub上的算法教程项目,包含了多种算法的实现和解释,适合希望提高算法能力的开发者。
后续学习指引
正式实验题目列表
基础阶段
| 编号 | 位置 | 简介 | 考察点 | 难度 |
|---|---|---|---|---|
| 01 | src/exercise-01 | 编写第一个 Makefile | 程序构建 | 入门 |
| 02 | src/exercise-02 | 编写第一个测试 | 程序构建 | 入门 |
| 03 | src/exercise-03 | 使用 Makefile 静态链接程序 | 程序构建 | 入门 |
| 04 | src/exercise-04 | 使用 Makefile 构建第一个静态链接库 | 程序构建 | 入门 |
| 05 | src/exercise-05 | 使用 Makefile 构建第一个动态链接库 | 程序构建 | 入门 |
| 11 | src/exercise-11 | 编写一个简单的 ld 文件并指定内存区域 | 程序构建 | 基础 |
| 12 | src/exercise-12 | 编写一个简单的 ld 文件并指定 text 起始地址 | 程序构建 | 基础 |
| 13 | src/exercise-13 | 编写一个简单的 ld 文件并指定自定义 symbol | 程序构建 | 基础 |
| 14 | src/exercise-14 | 编写一个简单的 ld 文件并指定自定义 section | 程序构建 | 基础 |
| 20 | src/exercise-20 | 合并两个任务队列 | 数据结构 | 基础 |
| 21 | src/exercise-21 | 按组反转一个任务队列 | 数据结构 | 基础 |
| 30 | src/exercise-30 | 编写一个内核模块打印 hello world | 内核模块 | 入门 |
| 31 | src/exercise-31 | 编写一个内核模块实现阶乘计算 | 内核模块 | 基础 |
| 32 | src/exercise-32 | 编写一个内核模块实现字符串反转 | 内核模块 | 基础 |
| 33 | src/exercise-33 | 编写一个内核模块实现平均数计算 | 内核模块 | 基础 |
| 34 | src/exercise-34 | 编写一个内核模块实现线性查找 | 内核模块 | 基础 |
| 35 | src/exercise-35 | 编写一个内核模块延时打印字符串 | 内核模块 | 入门 |
| 40 | src/exercise-40 | 使用 RISC-V 内联汇编实现条件返回 | RISC-V 基础指令 | 基础 |
| 41 | src/exercise-41 | 使用 RISC-V 内联汇编实现最大公因数求解 | RISC-V 基础指令 | 基础 |
| 42 | src/exercise-42 | 使用 RISC-V 内联汇编实现数组元素查找 | RISC-V 基础指令 | 中等 |
进阶阶段
| 编号 | 位置 | 简介 | 考察点 | 难度 |
|---|---|---|---|---|
| 22 | src/exercise-22 | 矩阵相乘 | 矩阵 | 基础 |
| 23 | src/exercise-23 | 2D 卷积操作 | 矩阵 | 基础 |
| 24 | src/exercise-24 | 矩阵的原地转置 | 矩阵 | 基础 |
| 25 | src/exercise-25 | 包含 0 的行列进行矩阵置零 | 矩阵 | 基础 |
| 26 | src/exercise-26 | 查找矩阵中第 K 个最小的元素 | 矩阵 | 基础 |
| 36 | src/exercise-36 | 编写一个内核模块求最大值 | 内核模块 | 基础 |
| 37 | src/exercise-37 | 编写一个内核模块启动一个定时器 | 内核模块 | 基础 |
| 38 | src/exercise-38 | 编写一个内核模块创建一个虚拟字符设备 | 内核模块 | 中等 |
| 39 | src/exercise-39 | 编写一个内核模块实现一个简单的文件操作函数 | 内核模块 | 中等 |
| 43 | src/exercise-43 | 使用内联 RISCV 汇编实现计算斐波那契数列的第 n 个数 | RISC-V 基础指令RISC-V 基础指令 | 中等 |
| 44 | src/exercise-44 | 使用内联 RISCV 汇编实现整数数组求和 | RISC-V 基础指令 | 中等 |
| 45 | src/exercise-45 | 使用内联 RISCV 汇编实现查找整数数组最大值 | RISC-V 基础指令 | 中等 |
| 46 | src/exercise-46 | 使用内联 RISCV 汇编实现判断给定数组是否有序 | RISC-V 基础指令 | 中等 |
| 47 | src/exercise-47 | 使用内联 RISCV 汇编实现给定数组目标元素个数 | RISC-V 基础指令 | 中等 |
| 50 | src/exercise-50 | 模拟 FIFO 页面置换算法 | 操作系统 | 中等 |
| 51 | src/exercise-51 | 模拟 LRU 页面置换算法 | 操作系统 | 中等 |
| 52 | src/exercise-52 | 获取容器主机名 | 操作系统 | 基础 |
| 53 | src/exercise-53 | 简单虚拟地址到物理地址的转换 | 操作系统 | 中等 |
| 54 | src/exercise-54 | 模拟时间片轮转调度算法 | 操作系统 | 中等 |
| 55 | src/exercise-55 | 模拟虚拟内存限制 | 操作系统 | 中等 |
学习指引
基础阶段
- Makefile 基础
- 实验编号:01, 02, 03, 04, 05
- 学习目标:掌握 Makefile 的基本使用,包括编写简单的 Makefile、静态和动态链接库的构建。
- 学习步骤:
- 阅读相关文档,了解 Makefile 的基本语法和结构。
- 逐步完成每个实验,理解每个命令的作用。
- 尝试修改 Makefile,观察构建结果的变化。
- 链接器脚本编写
- 实验编号:11, 12, 13, 14
- 学习目标:学习如何编写链接器脚本,指定内存区域、text 起始地址、自定义符号和节。
- 学习步骤:
- 理解链接器脚本的基本概念和作用。
- 完成实验,注意观察链接结果与脚本的关系。
- 数据结构应用
- 实验编号:20, 21
- 学习目标:掌握基本的数据结构操作,如队列的合并和反转。
- 学习步骤:
- 复习队列的基本操作。
- 实现代码,测试不同情况下的队列操作。
- 内核模块开发
- 实验编号:30, 31, 32, 33, 34, 35
- 学习目标:学习内核模块的基本开发流程,包括打印信息、实现简单算法等。
- 学习步骤:
- 了解内核模块的基本概念和开发环境配置。
- 逐步完成每个实验,理解内核模块与用户态程序的区别。
- RISC-V 内联汇编
- 实验编号:40, 41, 42
- 学习目标:学习 RISC-V 内联汇编的基本使用,实现简单的算法。
- 学习步骤:
- 学习 RISC-V 指令集基础。
- 编写汇编代码,理解汇编与 C 语言的交互。
进阶阶段
- 矩阵操作
- 实验编号:22, 23, 24, 25, 26
- 学习目标:深入理解矩阵操作,包括矩阵乘法、卷积、转置和元素查找。
- 学习步骤:
- 学习矩阵的基本数学性质。
- 实现代码,优化算法性能。
- 内核模块高级应用
- 实验编号:36, 37, 38, 39
- 学习目标:学习内核模块的高级应用,如定时器、虚拟设备和文件操作。
- 学习步骤:
- 深入理解内核模块的工作原理。
- 完成实验,注意安全性和稳定性。
- RISC-V 内联汇编高级应用
- 实验编号:43, 44, 45, 46, 47
- 学习目标:掌握 RISC-V 内联汇编的高级应用,实现复杂算法。
- 学习步骤:
- 深入学习 RISC-V 指令集。
- 编写复杂的汇编代码,优化性能。
- 操作系统原理
- 实验编号:50, 51, 52, 53, 54, 55
- 学习目标:理解操作系统的基本原理,如页面置换算法、地址转换和调度算法。
- 学习步骤:
- 学习操作系统的基本概念和原理。
- 实现模拟算法,理解操作系统的工作机制。
部分优质实践资源
清华大学开源操作系统训练营
开源操作系统训练营是由清华大学的陈渝老师和向勇老师于2020年发起,旨在通过使用Rust语言编写操作系统的实践,培养全国高校学生的操作系统开发技能。训练营全程免费,指导学员参与开源项目实战,探索设计与构建新一代安全高性能操作系统。
自动驾驶OS开发训练营
自动驾驶OS开发训练营是国家智联网联汽车创新中心(简称“创新中心”)和清华大学携手打造的前沿技术培训项目,课程内容汲取了清华大学Rust OS训练营的精髓,紧密结合自动驾驶操作系统领域的应用实践,致力于为在校学生及自动驾驶领域的从业人员提供专业、系统的自动驾驶OS开发技能与知识培训,成为符合行业需求的优秀工程师。
一生一芯
针对我国计算机专业当前面临的较为突出的人才培养问题,以及计算机处理器芯片设计人才不足的问题,中国科学院大学(简称“国科大”)计算机科学与技术学院立足已有的理论课堂与实验教学,联合中国科学院计算技术研究所(简称“计算所”)的科研工程支撑团队,于2019年8月启动了“一生一芯”开源处理器芯片教学流片实践项目计划。
全国大学生计算机系统能力大赛
全国大学生计算机系统能力大赛是由系统能力培养研究专家组发起、由全国高校计算机教育研究会主办,面向高校大学生举办的全国性大赛,以学科竞赛推动专业建设和计算机领域创新人才培养体系改革、培育我国高端芯片及核心系统的技术突破与产业化后备人才为目标,是我国高校系统能力相关的高水平学科竞赛。目前,大赛设置CPU设计赛、操作系统赛、编译系统赛、数据库设计赛多个赛道。
开源之夏
开源之夏是由中国科学院软件研究所“开源软件供应链点亮计划”发起并长期支持的一项暑期开源活动,旨在鼓励在校学生积极参与开源软件的开发维护,培养和发掘更多优秀的开发者,促进优秀开源软件社区的蓬勃发展,助力开源软件供应链建设。
其余常见问题与解决方案
1.导学阶段的实验是一定要完成的吗?
虽然导学阶段的实验并非强制性要求完成,但我们强烈推荐每位学员积极参与。导学阶段的实验设计旨在帮助学员熟悉正式阶段实验的评测流程,包括代码提交、版本控制系统的使用以及持续集成(CI)的评测机制。通过完成这些实验,学员可以提前预演在正式阶段可能遇到的各种情况,从而减少正式实验时的困惑和错误,提高学习效率。
2.导学阶段的课程一定要全部完成吗?
与实验类似,导学阶段的课程也是推荐完成而非强制。这些课程涵盖了操作系统的基础知识和关键概念,对于没有相关背景的学员来说,是理解后续复杂概念和实验的基础。完成导学阶段的课程可以帮助学员建立坚实的知识基础,为后续更深入的学习和实践打下良好的基础。
3.导学阶段实验的环境配置是否与正式实验相同?
导学阶段的环境配置相对简单,主要是为了让学员快速上手并熟悉实验流程。而正式实验的环境配置则更为复杂,除了基本的环境设置外,还需要配置交叉编译工具链和本地QEMU环境。为了简化这一过程,我们提供了可以直接在QEMU中运行的工具链镜像。这意味着,一旦完成了导学阶段的实验,学员可以利用这些资源快速过渡到正式实验的环境配置,减少不必要的时间浪费。
4.为何要在导学阶段设置实验?
导学阶段的实验设置主要是为了帮助学员适应远程实验的模式,特别是对于那些初次接触通过提交代码到远程仓库并通过CI进行评测的学员。这种模式在现代软件开发中非常常见,因此提前熟悉这一流程对于学员未来的学习和职业生涯都有很大帮助。此外,导学阶段的实验还可以帮助学员建立信心,通过实际操作来验证和巩固理论知识,为正式阶段的实验打下坚实的基础。
附录A:使用 Gitee 流水线信息进行调试
在软件开发过程中,持续集成和持续部署(CI/CD)是确保代码质量和加快交付速度的关键环节。Gitee 提供了流水线服务,帮助开发者自动化构建、测试和部署流程。当流水线出现问题时,如何有效地进行调试成为了一个重要课题。本章节将介绍如何使用 Gitee 流水线信息进行调试。
理解 Gitee 流水线
在开始调试之前,首先需要理解 Gitee 流水线的基本概念和工作流程。Gitee 流水线基于 Git 仓库的提交触发,可以配置多个阶段,每个阶段包含一系列任务。这些任务可以是编译代码、运行测试、部署应用等。
获取流水线信息
当流水线执行失败时,第一步是获取相关的流水线信息。在 Gitee 仓库的流水线页面,你可以看到流水线的执行历史,包括每个阶段的执行状态和日志。点击具体的流水线执行记录,可以查看详细的日志信息。
查看日志
日志是调试流水线问题的关键。Gitee 流水线提供了详细的日志输出,包括每个任务的输入、输出和错误信息。通过分析日志,你可以定位到问题所在。
检查配置
流水线的配置文件定义了流水线的行为。检查配置文件是否正确,包括环境变量、脚本命令、依赖项等,是调试的重要步骤。
调试步骤
1. 重现问题
如果可能,尝试重现流水线失败的情况。这通常意味着你需要模拟相同的提交或触发条件。
2. 缩小问题范围
通过分析日志和配置,尝试缩小问题的范围。确定是哪个任务或脚本导致了问题。
3. 本地测试
在本地环境中复现流水线中的任务。这可以帮助你验证假设,并确定问题是否与环境有关。
4. 修改配置
根据调试结果,修改流水线配置。这可能包括更新脚本、修复依赖项或调整环境变量。
5. 重新触发流水线
提交更改后,重新触发流水线。观察新的执行结果,确认问题是否得到解决。
使用 Gitee 流水线调试工具
Gitee 流水线提供了一些工具来帮助调试:
- 环境变量:在流水线配置中设置环境变量,可以在任务中使用这些变量进行调试。
- 缓存:合理使用缓存可以加快流水线执行速度,减少因依赖安装导致的失败。
- 自定义脚本:编写自定义脚本进行更复杂的调试操作。
附录B:实验所用到的其余专业前置知识
C++ STL
C++ 标准模板库(Standard Template Library,STL)是 C++ 标准库的一部分,提供了一系列的模板类和函数,用于实现常用的数据结构和算法。STL 的设计理念是“泛型编程”,即通过模板技术使得算法和数据结构可以独立于具体的数据类型。STL 主要包含以下几个组件:
1. 容器(Containers)
容器是用来存储数据的对象,STL 提供了多种容器,每种容器都有其特定的用途和性能特点。常见的容器包括:
- 向量(vector):动态数组,支持随机访问。
- 列表(list):双向链表,支持高效的插入和删除操作。
- 双端队列(deque):双端队列,支持两端高效插入和删除。
- 集合(set):存储不重复元素的集合,内部通常使用平衡二叉树实现。
- 多重集合(multiset):与 set 类似,但允许元素重复。
- 映射(map):键值对的集合,内部通常使用平衡二叉树实现。
- 多重映射(multimap):与 map 类似,但允许键重复。
- 栈(stack):后进先出(LIFO)的数据结构。
- 队列(queue):先进先出(FIFO)的数据结构。
- 优先队列(priority_queue):元素出队顺序由优先级决定。
2. 迭代器(Iterators)
迭代器是连接算法和容器的桥梁,它提供了一种统一的方式来访问容器中的元素。STL 中的迭代器分为几种类型,包括输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器。
3. 算法(Algorithms)
STL 提供了一系列的算法,这些算法可以作用于不同类型的容器。常见的算法包括排序(sort)、搜索(find)、合并(merge)、复制(copy)、替换(replace)等。这些算法通常都是通过迭代器来操作容器中的元素。
4. 函数对象(Function Objects)
函数对象,也称为仿函数,是重载了函数调用操作符 () 的类对象。它们可以像普通函数一样被调用,同时也可以保存状态或者进行类型检查。STL 中的许多算法都接受函数对象作为参数,以实现自定义的行为。
5. 适配器(Adapters)
适配器是一种特殊的容器或函数对象,它们通过改变其他容器或函数对象的接口来提供新的接口。例如,栈和队列就是通过适配器实现的,它们分别基于向量和双端队列,但提供了不同的接口。
分配器负责管理容器中元素的内存分配和释放。STL 默认使用 std::allocator,但用户也可以自定义分配器以满足特定的内存管理需求。
STL 的设计使得数据结构和算法的实现与具体的数据类型无关,这大大提高了代码的复用性和灵活性。通过使用 STL,开发者可以更加专注于算法的设计和实现,而不必重复编写基本的数据结构和算法。
Shell
Shell 是一种命令行解释器,它为用户提供了一个与操作系统内核进行交互的界面。通过 shell,用户可以输入命令,执行程序,管理文件和系统等。Shell 不仅是一个命令解释器,还是一个强大的编程环境,允许用户编写脚本来自动化复杂的任务。
常见的 Shell 类型
- Bash (Bourne Again SHell):这是最常用的 shell,它是 GNU 项目的一部分,广泛用于 Linux 和 macOS 系统。
- sh (Bourne Shell):由 Stephen Bourne 在 AT&T 开发,是许多其他 shell 的基础。
- csh (C Shell):语法类似于 C 语言,提供了一些额外的功能,如命令历史和别名。
- tcsh (TENEX C Shell):csh 的增强版本,增加了命令行编辑和命令补全等功能。
- zsh (Z Shell):一个功能强大的 shell,集成了许多其他 shell 的特性,并提供了许多增强功能。
- fish (Friendly Interactive SHell):设计用于提供用户友好的体验,包括自动建议和语法高亮。
Shell 的基本功能
- 命令执行:用户可以直接在 shell 中输入命令,shell 会解释并执行这些命令。
- 文件系统导航:使用
cd、ls、pwd等命令来浏览和管理文件系统。 - 重定向和管道:允许用户将命令的输入输出重定向到文件或其他命令,使用
|符号可以将一个命令的输出作为另一个命令的输入。 - 环境变量:用户可以设置环境变量来影响命令的行为,例如
PATH变量定义了命令的搜索路径。 - 脚本编程:用户可以编写 shell 脚本来执行一系列命令,脚本可以包含条件判断、循环、函数等编程结构。
- 作业控制:用户可以启动、停止、恢复和终止后台作业。
Shell 脚本编程
Shell 脚本是一种简单的脚本语言,它允许用户将一系列命令组合成一个文件,以便自动执行。脚本可以包含变量、控制结构(如 if、for、while)、函数和命令。以下是一个简单的 Bash 脚本示例:
#!/bin/bash
# 这是一个简单的 Bash 脚本
echo "Hello, World!"
# 使用变量
name="Alice"
echo "Hello, $name!"
# 使用条件判断
if [ "$name" == "Alice" ]; then
echo "Welcome, Alice!"
fi
# 使用循环
for i in {1..5}; do
echo "Count: $i"
done
要运行这个脚本,首先需要给它执行权限,然后可以直接运行:
chmod +x script.sh
./script.sh
Shell 是系统管理员和开发人员的重要工具,它提供了强大的自动化和定制能力。通过学习和使用 shell,用户可以更高效地管理和操作计算机系统。
YAML
YAML("YAML Ain't Markup Language" 的递归缩写)是一种人类可读的数据序列化标准,广泛用于配置文件、数据交换、对象持久化等领域。YAML 的设计目标是使数据在不同编程语言之间交换变得简单,同时保持良好的可读性和简洁性。
YAML 的基本语法
- 缩进:YAML 使用缩进来表示数据结构中的层次关系。通常使用空格(推荐使用两个空格),不建议使用制表符。
- 冒号:用于表示键值对,冒号后面通常跟着一个空格。
- 短横线:用于表示列表项,短横线后面通常跟着一个空格。
- 注释:使用井号
#表示单行注释。 - 引用:可以使用
&定义锚点,使用*引用锚点。 - 字符串:字符串不需要引号,但如果包含特殊字符或需要跨行,可以使用单引号或双引号。
- 布尔值:可以使用
true、false、yes、no、on、off等。 - 空值:使用
null或~表示。
YAML 示例
以下是一个简单的 YAML 文件示例:
# 这是一个 YAML 示例文件
name: John Doe
age: 30
is_student: false
hobbies:
- reading
- hiking
- coding
contact:
email: john.doe@example.com
phone: 123-456-7890
address:
street: 123 Main St
city: Anytown
state: CA
zip: 12345
在这个示例中,name、age 和 is_student 是键值对,hobbies 是一个列表,contact 和 address 是嵌套的键值对。
YAML 的应用
YAML 常用于配置文件,因为它比 XML 和 JSON 更加简洁和易读。许多流行的软件和框架,如 Docker、Kubernetes、Ansible、Spring Boot 等,都使用 YAML 作为配置文件格式。
注意事项
- YAML 文件不区分大小写,但通常约定使用小写字母。
- 避免在 YAML 文件中使用特殊字符,除非它们被正确转义。
- 在处理 YAML 文件时,确保使用支持 YAML 标准的解析器。
YAML 是一种灵活且强大的数据序列化格式,它使得配置文件和数据交换更加简单和直观。通过学习和使用 YAML,开发者可以更有效地管理配置和数据。
附录C:部分工具的使用入门
vscode
Visual Studio Code(简称 VS Code)是一个由微软开发的免费、开源的代码编辑器。它支持多种编程语言,并且可以通过安装扩展来增强其功能。VS Code 因其强大的功能、高度的可定制性和良好的用户体验而广受欢迎。以下是 VS Code 的一些基本使用方法:
安装 VS Code
- 访问 VS Code 官网(https://code.visualstudio.com/)。
- 根据你的操作系统(Windows、macOS、Linux)下载对应的安装包。
- 按照安装向导完成安装。
界面概览
VS Code 的界面主要包括以下几个部分:
- 菜单栏:位于顶部,包含文件、编辑、查看等菜单。
- 侧边栏:包含资源管理器、搜索、源代码管理、运行和调试、扩展等视图。
- 编辑区:主要的工作区域,用于编辑代码。
- 状态栏:位于底部,显示当前文件的信息、语言模式、缩进等。
基本操作
- 打开文件或文件夹:通过“文件”菜单或快捷键
Ctrl+O(Windows/Linux)或Cmd+O(macOS)打开文件,通过“文件”菜单或快捷键Ctrl+K Ctrl+O打开文件夹。 - 编辑代码:在编辑区中直接输入或修改代码。
- 保存文件:通过“文件”菜单或快捷键
Ctrl+S(Windows/Linux)或Cmd+S(macOS)保存文件。 - 代码折叠:使用快捷键
Ctrl+Shift+[和Ctrl+Shift+]折叠和展开代码块。 - 代码导航:使用快捷键
Ctrl+Tab在打开的文件之间切换,使用Ctrl+或Cmd+点击函数或变量跳转到定义。
使用扩展
VS Code 的强大之处在于其丰富的扩展生态。你可以通过以下步骤安装和管理扩展:
- 点击侧边栏的“扩展”图标或使用快捷键
Ctrl+Shift+X。 - 在搜索框中输入扩展名称,找到后点击“安装”。
- 安装后,扩展会自动启用,你也可以在扩展管理页面进行配置或卸载。
调试代码
VS Code 内置了调试功能,可以用来调试多种语言的代码:
- 点击侧边栏的“运行和调试”图标或使用快捷键
Ctrl+Shift+D。 - 点击“创建 launch.json”文件来配置调试环境。
- 设置断点,然后点击“开始调试”按钮或使用快捷键
F5。
其他功能
- 终端:通过“查看”菜单或快捷键
Ctrl+打开集成终端,可以在不离开编辑器的情况下执行命令。 - 版本控制:VS Code 内置了 Git 支持,可以通过侧边栏的“源代码管理”视图进行版本控制操作。
- 任务运行:可以配置任务来自动化编译、测试等操作,通过“终端”菜单或快捷键
Ctrl+Shift+B运行任务。
vim/neovim
Vim(Vi IMproved)和 Neovim 是两个流行的文本编辑器,它们都是从 Vi 编辑器发展而来的。Vim 和 Neovim 都以其强大的功能、高度的可定制性和高效的键盘操作而闻名。以下是 Vim 和 Neovim 的一些基本使用方法:
启动 Vim/Neovim
在命令行中输入 vim 或 nvim 即可启动 Vim 或 Neovim。如果想要编辑一个文件,可以在命令后面加上文件名,例如 vim file.txt 或 nvim file.txt。
模式
Vim/Neovim 有几种不同的模式:
- 普通模式(Normal Mode):启动 Vim/Neovim 后默认进入的模式,用于导航、执行命令和切换到其他模式。
- 插入模式(Insert Mode):用于输入文本,通过按
i(插入)、a(追加)等键进入。 - 命令行模式(Command-line Mode):用于执行命令,如保存文件、搜索替换等,通过按
:进入。 - 可视模式(Visual Mode):用于选择文本,通过按
v(字符可视)、V(行可视)或Ctrl+v(块可视)进入。
基本操作
- 移动光标:在普通模式下,使用方向键或
h(左)、j(下)、k(上)、l(右)移动光标。 - 插入文本:在普通模式下按
i进入插入模式,输入文本后按Esc返回普通模式。 - 保存和退出:在普通模式下按
:进入命令行模式,输入w(保存)、q(退出)或wq(保存并退出)。 - 删除文本:在普通模式下,使用
x(删除字符)、dd(删除行)等命令。 - 撤销和重做:在普通模式下,使用
u(撤销)和Ctrl+r(重做)。
高级操作
- 搜索和替换:在命令行模式下,使用
/进行搜索,使用:%s/old/new/g进行全局替换。 - 复制和粘贴:在普通模式下,使用
yy(复制行)、p(粘贴)等命令。 - 多窗口:在命令行模式下,使用
:split或:vsplit创建新窗口。 - 宏录制:在普通模式下,使用
q开始录制宏,使用q停止录制,使用@播放宏。
配置
Vim/Neovim 可以通过配置文件进行高度定制。Vim 的配置文件通常是 ~/.vimrc,而 Neovim 的配置文件是 ~/.config/nvim/init.vim。你可以在这些文件中设置选项、映射快捷键、加载插件等。
插件管理
Vim/Neovim 支持通过插件扩展功能。对于 Vim,可以使用 Vundle、Pathogen 等插件管理器。对于 Neovim,可以使用 vim-plug、dein.vim 等。安装插件管理器后,你可以在配置文件中列出想要安装的插件,然后运行相应的命令来安装它们。
学习资源
:help:在 Vim/Neovim 中输入:进入命令行模式,然后输入help可以查看帮助文档。- 在线教程:有许多在线资源和教程可以帮助你学习 Vim/Neovim,例如 Vim 的官方网站(https://www.vim.org/)和 Neovim 的 GitHub 页面(https://github.com/neovim/neovim)。
Vim/Neovim 的学习曲线可能比较陡峭,但一旦掌握了基本操作和一些高级技巧,你将能够以非常高效的方式编辑文本和代码。随着实践的深入,你会发现 Vim/Neovim 的强大之处,并能够根据自己的需求进行定制。
Clion
CLion 是由 JetBrains 开发的一款跨平台的集成开发环境(IDE),专为 C 和 C++ 开发而设计。它提供了代码编辑、调试、项目管理、代码分析等一系列功能,旨在提高开发效率。以下是 CLion 的一些基本使用方法:
安装 CLion
- 访问 CLion 官网(https://www.jetbrains.com/clion/)。
- 下载适用于你操作系统的安装包。
- 按照安装向导完成安装。
界面概览
CLion 的界面主要包括以下几个部分:
- 菜单栏:位于顶部,包含文件、编辑、导航、代码、分析、重构、运行、工具、VCS 等菜单。
- 工具栏:包含常用的操作按钮,如新建项目、打开文件、保存、运行、调试等。
- 编辑区:主要的工作区域,用于编辑代码。
- 侧边栏:包含项目视图、结构视图、TODO 视图等。
- 状态栏:位于底部,显示当前文件的信息、编译状态、错误和警告等。
基本操作
- 创建项目:通过“文件”菜单或工具栏上的“新建项目”按钮创建新项目。
- 打开文件:通过“文件”菜单或工具栏上的“打开”按钮打开文件。
- 编辑代码:在编辑区中直接输入或修改代码。
- 保存文件:通过“文件”菜单或快捷键
Ctrl+S(Windows/Linux)或Cmd+S(macOS)保存文件。 - 代码导航:使用快捷键
Ctrl+或Cmd+点击函数或变量跳转到定义,使用Ctrl+Alt+Left/Right在编辑历史中导航。
编译和运行
CLion 集成了 CMake 作为项目构建系统,可以自动管理编译过程:
- 在侧边栏的“项目”视图中,可以看到 CMakeLists.txt 文件,这是 CMake 的配置文件。
- 点击工具栏上的“编译”按钮或使用快捷键
Ctrl+F9编译项目。 - 点击工具栏上的“运行”按钮或使用快捷键
Shift+F10运行项目。
调试
CLion 提供了强大的调试功能,可以帮助你定位和修复代码中的问题:
- 在代码中设置断点,通过点击行号旁边的空白区域。
- 点击工具栏上的“调试”按钮或使用快捷键
Shift+F9启动调试。 - 在调试过程中,可以使用调试工具栏上的按钮进行单步执行、查看变量值、检查调用栈等操作。
代码分析和重构
CLion 提供了代码分析工具,可以帮助你发现潜在的错误和改进代码质量:
- 通过“代码”菜单中的“检查代码”功能,CLion 会自动分析代码并给出建议。
- 使用“重构”菜单中的功能,如重命名、提取函数、内联变量等,可以安全地修改代码结构。
版本控制
CLion 内置了对 Git 等版本控制系统的支持:
- 通过“VCS”菜单或侧边栏的“版本控制”视图,可以进行提交、拉取、推送等操作。
- 在编辑区中,可以通过颜色标记查看文件的修改状态。
插件和配置
CLion 支持通过插件扩展功能,你可以在“设置/首选项”对话框中安装和管理插件。此外,你还可以在“设置/首选项”中配置编辑器、快捷键、外观等选项,以满足个人偏好。