前言
大家好!经过了基础阶段的努力学习,相信大家已对计算机有了基本的了解。希望大家能在进阶阶段学到更多内容,并在之后的学习中取得更大的进步。
在本书中,我们将基于基础阶段之上进一步加大难度,同时会带领大家串讲基础阶段的知识,并拓展新的内容————正所谓温故而知新。我们默认进入此阶段后你们已掌握了环境搭建、基础编程、基础操作系统等知识,故本书也将不再详细介绍这些内容。
本阶段主要将从以下几个理论课开展:
- 虚拟内存与物理内存管理
- 系统虚拟化与容器
- RISC-V向量拓展基础与优化基础C库实践
同时为了提升大家的实战能力,便于完成我们的课后练习题,我们后面又为大家准备了大量的实战编程方面的教学内容:
- 矩阵与卷积算法
- Linux内核模块
- RISC-V架构内联汇编
- 操作系统常用算法
- Linux系统编程基础
希望大家从这里扬帆起航,取得好成绩!
虚拟内存与物理内存管理
操作系统在 RISC-V 架构上的虚拟内存和物理内存管理涉及多个方面,包括地址转换、页表、内存保护等。
教程与学习资源
-
RISC-V 规范:
- RISC-V Privileged Architecture Specification:详细描述了 RISC-V 的特权架构,包括虚拟内存管理。
-
RISC-V 模拟器:
-
RISC-V 操作系统教程:
-
书籍与文档:
- 《操作系统原理》:经典操作系统教材,涵盖虚拟内存管理的基础知识。
- 《Computer Organization and Design RISC-V Edition》:详细介绍了 RISC-V 架构及其内存管理。
通过这些资源,你可以深入学习 RISC-V 架构下的虚拟内存和物理内存管理机制,并实践相关知识。
虚拟内存与物理内存管理概念
虚拟地址和物理地址
虚拟地址
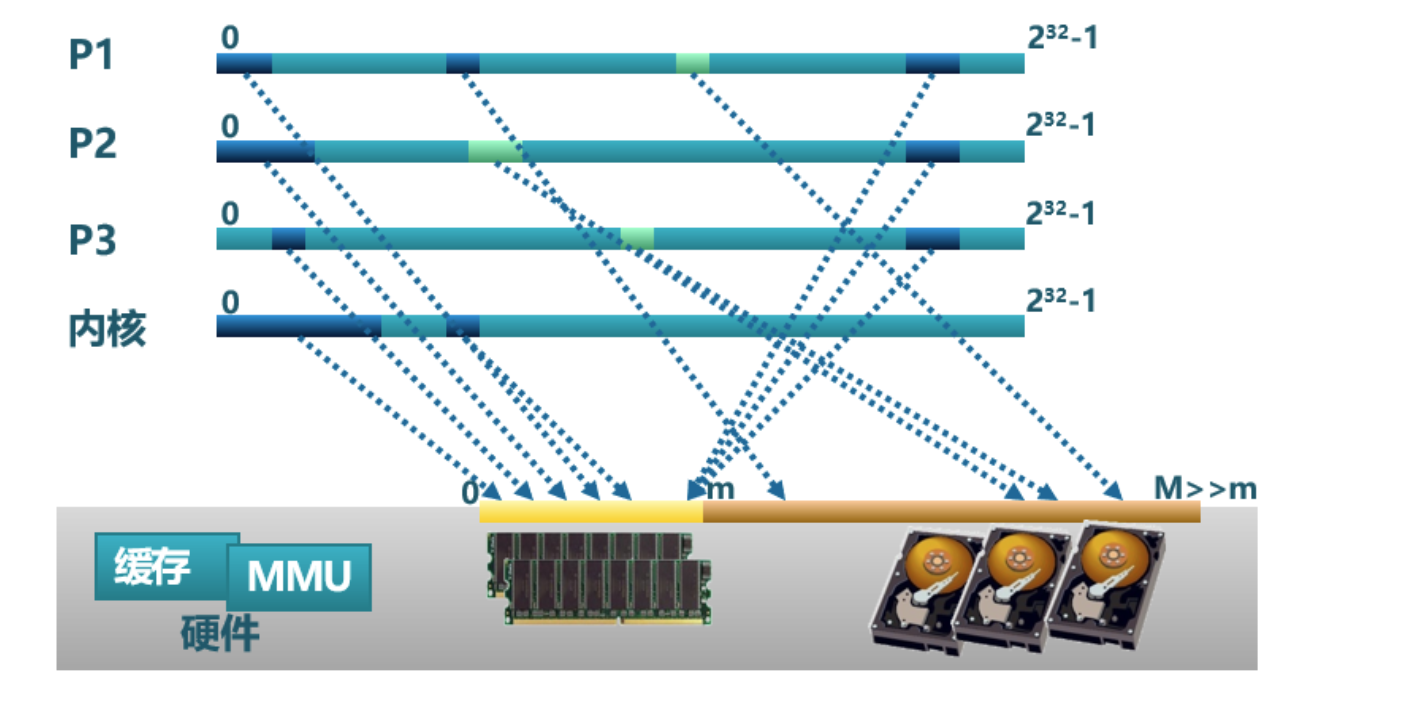
虚拟地址是指进程在运行时使用的地址。每个进程都认为自己独占整个内存空间,实际上,这些地址是通过操作系统的内存管理单元(MMU)映射到实际的物理内存地址。虚拟地址的引入使得程序的内存访问更加灵活和安全,避免了不同进程间的直接内存冲突。
物理地址
物理地址是指实际的硬件内存地址,是计算机内存的真正位置。物理地址是由硬件直接访问的,不同进程的虚拟地址会通过页表映射到不同的物理地址上,从而实现内存的隔离和保护。
页表 (Page Table)
页表的作用
页表用于将虚拟地址转换为物理地址。每个进程都有一个或多个页表,用于维护其虚拟地址到物理地址的映射关系。操作系统通过页表来管理进程的内存空间,确保每个进程的虚拟地址空间正确映射到物理内存上。
页表条目 (PTE, Page Table Entry)
页表条目包含了虚拟页号 (VPN, Virtual Page Number) 和物理页号 (PPN, Physical Page Number) 的映射关系。每个页表条目还可能包含一些控制信息,如页的有效位、读/写权限、缓存策略等。
多级页表 (Multilevel Page Table)
多级页表的必要性
多级页表用于减少内存开销和页表大小。在大地址空间中,如果使用单级页表,页表会非常大且占用大量内存。多级页表通过将页表分为多个层次,每层次管理一部分地址空间,从而减少单个页表的大小。
RISC-V 的多级页表
RISC-V 通常使用两级或三级页表来管理大地址空间。每一级页表指向下一级页表或最终的物理页号。通过多级页表结构,RISC-V 可以高效地管理和映射大地址空间,同时减少页表占用的内存。
页大小 (Page Size)
页大小的多样性
RISC-V 支持多种页大小,如 4KB、2MB 和 1GB,以适应不同应用需求。小页适合细粒度的内存管理,大页适合大块数据的快速访问。不同页大小的灵活性使得系统可以根据具体应用的需求选择合适的页大小,提高内存管理效率。
地址转换缓冲区 (TLB, Translation Lookaside Buffer)
TLB 的作用
TLB 是一种高速缓存,用于快速查找和转换虚拟地址到物理地址。由于页表存储在内存中,频繁的地址转换会带来显著的性能开销。TLB 缓存常用的页表条目,大大加快地址转换速度,减少访问内存的延迟。
TLB 的工作原理
TLB 存储着最近使用的虚拟地址到物理地址的映射。当CPU需要访问某个虚拟地址时,会首先查询TLB。如果找到对应的物理地址,则直接使用;如果没有找到,则需要查找页表,并将结果存入TLB,以备下次使用。TLB 的高命中率可以显著提高系统性能。
总结
通过虚拟地址、物理地址、页表、多级页表、页大小和TLB的协同工作,现代计算机系统能够高效地管理内存,为每个进程提供独立的虚拟地址空间,同时提高内存访问速度和系统整体性能。这些概念和机制共同构成了操作系统内存管理的核心,确保系统的稳定性、安全性和高效性。
RISC-V 虚拟内存管理机制
虚拟内存模式:Sv32、Sv39 和 Sv48
RISC-V 支持多种虚拟内存模式,以适应不同的地址空间需求:
-
Sv32 (32-bit 虚拟地址)
- 适用于简单的系统和嵌入式应用。
- 支持 32 位虚拟地址空间(4 GB)。
- 使用两级页表,每级页表有 1024 个条目。
- 每个页表条目大小为 4 字节。
-
Sv39 (39-bit 虚拟地址)
- 常用于中等规模的系统。
- 支持 39 位虚拟地址空间(512 GB)。
- 使用三级页表,每级页表有 512 个条目。
- 每个页表条目大小为 8 字节。
-
Sv48 (48-bit 虚拟地址)
- 适用于大型系统和服务器应用。
- 支持 48 位虚拟地址空间(256 TB)。
- 使用四级页表,每级页表有 512 个条目。
- 每个页表条目大小为 8 字节。
页表基地址寄存器 (SATP, Supervisor Address Translation and Protection)
SATP 寄存器是 RISC-V 中用于管理页表的关键寄存器。它存储当前使用的页表基地址和地址转换模式。SATP 寄存器的结构如下:
- Mode:地址转换模式,指示当前使用的虚拟内存模式(如 Sv32、Sv39 或 Sv48)。
- ASID:地址空间标识符,用于多进程环境中区分不同进程的地址空间。
- PPN:页表根页的物理页号,指示页表在物理内存中的位置。
操作系统通过设置 SATP 寄存器来控制虚拟地址到物理地址的映射。
页表结构与多级页表
不同虚拟内存模式的页表结构各不相同,但其核心思想是相似的。以 Sv39 为例,解释多级页表的工作原理:
- VPN[2]:最高 9 位,索引第一级页表。
- VPN[1]:中间 9 位,索引第二级页表。
- VPN[0]:最低 9 位,索引第三级页表。
- Offset:页内偏移,12 位。
虚拟地址在转换为物理地址时,按照上述三级页表逐级查找,最终得到物理页号 (PPN) 和页内偏移组合成物理地址。
页表条目 (PTE, Page Table Entry)
每个页表条目包含以下信息:
- V:有效位,指示该条目是否有效。
- R:读权限位。
- W:写权限位。
- X:执行权限位。
- U:用户态权限位。
- G:全局位。
- A:访问位,指示页是否被访问。
- D:脏位,指示页是否被修改。
- PPN:物理页号,指示虚拟页映射到的物理页。
这些位的组合决定了该页的属性和权限。
地址转换缓冲区 (TLB, Translation Lookaside Buffer)
TLB 是一种高速缓存,用于快速查找和转换虚拟地址到物理地址。由于页表存储在内存中,频繁的地址转换会带来显著的性能开销。TLB 缓存常用的页表条目,大大加快地址转换速度,减少访问内存的延迟。
异常处理
当发生页错误 (Page Fault) 时,硬件会触发异常,操作系统捕获并处理这些异常。页错误通常由以下原因引起:
- 缺页异常:访问的虚拟页没有映射到物理内存。
- 权限异常:访问权限不符合要求(如读写权限不足)。
- 非法地址:访问的虚拟地址不在进程的地址空间范围内。
操作系统在处理页错误时,通常会执行以下步骤:
- 缺页异常处理:分配新的物理页并更新页表条目,使虚拟页正确映射到物理页。
- 权限异常处理:调整页表条目的权限位,确保进程的内存访问符合权限要求。
- 非法地址处理:终止进程或采取其他安全措施,防止非法访问。
页表管理过程
- 页表初始化:操作系统在初始化时为每个进程创建页表,并设置 SATP 寄存器指向根页表。
- 页表查找:当 CPU 需要转换虚拟地址时,首先查找 TLB。如果命中,直接得到物理地址;如果未命中,按照多级页表逐级查找,最终得到物理地址。
- 页表更新:当进程需要分配或释放内存时,操作系统会更新相应的页表条目,确保虚拟地址正确映射到物理地址。
- 页表回收:当进程结束时,操作系统会回收其页表,释放内存资源。
页大小和大页支持
不同大小的页可以在页表中混合使用,以提高内存管理的灵活性和效率。SV39 支持三种页大小:
- 4KB:最小页,用于细粒度内存管理。
- 2MB:中等大小页,用于中等大小数据的管理。
- 1GB:大页,用于大块数据的快速访问。
不同大小的页使系统能够根据具体应用需求选择合适的页大小,从而优化内存管理效率。
- RISC-V 特权态下的页表管理机制通过虚拟内存模式、SATP 寄存器、多级页表结构、页表条目、TLB 和异常处理的协同工作,实现了高效的内存管理。操作系统通过这些机制为每个进程提供独立的虚拟地址空间,提高系统的安全性、稳定性和性能。
RISC-V 操作系统的虚拟化与容器技术详解
虚拟化和容器技术是现代操作系统中至关重要的两种技术,它们为应用提供了隔离、安全性和资源管理。RISC-V 作为一种开放的指令集架构,支持这些技术的实现。以下是对 RISC-V 操作系统中虚拟化与容器技术的详细讲解。
本章内容
本章介绍
RISC-V 操作系统中的虚拟化与容器技术通过硬件和软件的协同工作,实现了高效的资源管理和应用隔离。虚拟化技术提供了运行多个操作系统的能力,而容器技术提供了轻量级的应用隔离和快速部署能力。这些技术的结合,使得 RISC-V 平台能够支持复杂的应用场景,满足多样化的计算需求。
虚拟化技术
虚拟化技术允许在一台物理机器上运行多个虚拟机 (VM),每个虚拟机都可以运行一个操作系统。虚拟化技术包括硬件虚拟化、全虚拟化、半虚拟化和硬件辅助虚拟化。
-
硬件虚拟化 (Hardware Virtualization)
- 定义:直接在硬件上运行虚拟机管理程序 (Hypervisor)。
- RISC-V 支持:RISC-V 架构提供了特权指令集 (Privilege Architecture),包括机器模式 (M-mode)、监督模式 (S-mode) 和用户模式 (U-mode),这为硬件虚拟化提供了基础。
- 实现:Hypervisor 在 M-mode 运行,管理多个在 S-mode 运行的虚拟机。每个虚拟机有自己的页表和虚拟内存空间。
-
全虚拟化 (Full Virtualization)
- 定义:虚拟机运行未经修改的操作系统,Hypervisor 完全模拟底层硬件。
- RISC-V 支持:通过硬件辅助虚拟化扩展(如 hypervisor extension),RISC-V 可以实现全虚拟化。
- 实现:Hypervisor 拦截和处理所有的特权指令和硬件访问请求,提供完整的虚拟硬件环境。
-
半虚拟化 (Paravirtualization)
- 定义:虚拟机运行经过修改的操作系统,优化虚拟化性能。
- RISC-V 支持:操作系统需要修改以适应 RISC-V 虚拟化接口。
- 实现:虚拟机中的操作系统直接调用 Hypervisor 提供的接口,减少特权指令的开销,提高性能。
-
硬件辅助虚拟化 (Hardware-assisted Virtualization)
- 定义:通过硬件支持来简化和加速虚拟化操作。
- RISC-V 支持:RISC-V 的 hypervisor extension 提供了硬件支持,如虚拟机内存管理单元 (VMMU) 和虚拟化特权指令。
- 实现:Hypervisor 可以高效地管理虚拟机的内存和设备访问,减少上下文切换的开销。
容器技术
容器技术允许在同一操作系统内核上运行多个隔离的用户空间实例,每个实例被称为容器。容器技术包括操作系统级虚拟化、命名空间和控制组 (cgroups)。
-
操作系统级虚拟化 (Operating System-level Virtualization)
- 定义:容器共享宿主操作系统内核,但运行在隔离的用户空间。
- RISC-V 支持:RISC-V 操作系统(如 Linux)提供了支持容器的内核特性。
- 实现:通过容器引擎(如 Docker 或 Podman)在 RISC-V 上运行容器,每个容器有独立的文件系统、网络和进程空间。
-
命名空间 (Namespaces)
- 定义:命名空间是 Linux 内核提供的隔离机制,用于隔离系统资源。
- RISC-V 支持:RISC-V 架构上的 Linux 内核支持命名空间。
- 实现:不同的命名空间类型包括:
- PID 命名空间:隔离进程 ID。
- NET 命名空间:隔离网络接口和路由表。
- MNT 命名空间:隔离挂载点。
- UTS 命名空间:隔离主机名和域名。
- IPC 命名空间:隔离进程间通信。
- USER 命名空间:隔离用户和用户组 ID。
-
控制组 (cgroups)
- 定义:cgroups 是 Linux 内核提供的资源管理机制,用于限制和隔离资源使用。
- RISC-V 支持:RISC-V 架构上的 Linux 内核支持 cgroups。
- 实现:cgroups 允许为容器设置资源限制,如 CPU、内存、I/O 和网络带宽,确保容器间的资源分配和使用互不干扰。
容器与虚拟机的对比
- 性能:容器由于共享宿主内核,启动和运行效率高;虚拟机由于模拟硬件和运行独立内核,性能稍低。
- 隔离:虚拟机提供更强的隔离,因为每个虚拟机都有独立的内核;容器隔离相对较弱,但足以满足大多数应用场景。
- 资源使用:容器轻量级,占用更少的资源;虚拟机重量级,占用更多资源。
- 兼容性:虚拟机可以运行不同操作系统;容器通常运行与宿主相同的操作系统。
RISC-V向量拓展基础与优化基础C库实践
本章要求
- 掌握RISC-V向量拓展基础知识
- 掌握RISC-V向量拓展优化基础知识
- 掌握C语言中向量化编程的基本方法
- 掌握C语言中向量化编程的优化方法
主要内容
参考资料
-
RISC-V指令集架构手册 - 这是理解RISC-V架构的基础,包括其向量扩展和SIMD能力。
-
RISC-V Vector Extension Specification - 详细介绍了RISC-V的向量扩展,包括指令集和编程模型。
-
GCC编译器文档 - 包括如何使用GCC编译器进行RISC-V程序的编译和优化。
-
LLVM编译器文档 - LLVM项目也支持RISC-V,文档中包含了编译和优化RISC-V程序的相关信息。
-
RISC-V Software Development Tools - 介绍RISC-V软件开发工具,包括编译器、调试器和性能分析工具。
-
RISC-V International Conferences - RISC-V相关的国际会议论文集,包含最新的研究成果和开发实践。
-
RISC-V社区论坛和邮件列表 - 社区讨论和技术支持,可以获取关于RISC-V编程和优化的实用建议。
-
性能分析工具文档 - 如gprof和perf,这些工具可以帮助你分析程序的性能并识别优化点。
- gprof文档:通常包含在GCC的文档中。
- perf文档:perf Documentation
-
并行编程和优化书籍 - 这些书籍通常包含关于如何优化并行程序的通用策略,可以应用于RISC-V SIMD优化。
- 例如:"Parallel Programming for Multicore and Cluster Systems" by Mikel L. Z. Luque
-
学术期刊和会议论文 - 搜索与RISC-V SIMD和Unroll优化相关的学术论文,可以提供深入的技术分析和案例研究。
请注意,上述链接可能需要根据实际可用性和访问权限进行调整。在使用这些资源时,请确保遵循适当的引用规范和版权法规。
RISC-V 向量拓展 (V Extension) 基础
RISC-V 向量拓展 (Vector Extension, V) 是 RISC-V 指令集架构的一部分,旨在为高性能计算、机器学习、图像处理等领域提供高效的向量处理能力。向量拓展指令集支持单指令多数据 (SIMD) 操作,能够显著提高并行计算性能。
向量寄存器与指令集
-
向量寄存器
- RISC-V V 扩展提供了一组向量寄存器 (Vector Registers),每个寄存器可以存储多个数据元素。
- 向量寄存器的数量通常为 32 个,标识为 v0 到 v31。
- 每个向量寄存器的长度是可配置的,可以是 128 位、256 位、512 位等。
-
向量指令集
- RISC-V V 扩展定义了一组向量指令,用于对向量寄存器进行操作。这些指令包括但不限于:
- 加载/存储指令:用于在内存和向量寄存器之间传输数据。
- 算术运算指令:用于执行加法、减法、乘法、除法等运算。
- 逻辑运算指令:用于执行按位与、或、异或等操作。
- 比较指令:用于比较向量寄存器中的数据。
- 数据重排指令:用于重排、合并、拆分向量数据。
- RISC-V V 扩展定义了一组向量指令,用于对向量寄存器进行操作。这些指令包括但不限于:
SIMD 和向量化
-
SIMD (Single Instruction, Multiple Data)
- SIMD 是一种并行计算模式,在 RISC-V 向量扩展中得到了体现。
- SIMD 允许单条指令同时对多个数据元素进行操作,从而提高计算效率。
-
向量化
- 向量化是指将标量操作转换为向量操作,以利用 SIMD 指令的并行计算能力。
- 向量化可以通过手动编写向量指令,或者使用编译器自动向量化实现。
RISC-V C 语言计算库
为了在 C 语言中高效地利用 RISC-V 的向量拓展和 SIMD 指令,可以使用专门的计算库。这些库提供了高层次的 API,简化了向量指令的使用。
RISC-V 向量计算库
-
RVV Intrinsics
- RVV Intrinsics 是一组内嵌函数,允许在 C 语言中直接使用 RISC-V 向量指令。
- Intrinsics 函数通常以
__riscv_v_开头,如__riscv_v_add_vv用于向量加法。
-
使用示例
#include <riscv_vector.h> void vector_add(const int *a, const int *b, int *c, int n) { size_t vl; for (size_t i = 0; i < n; i += vl) { vl = vsetvl_e32m1(n - i); // 设置向量长度 vint32m1_t va = vle32_v_i32m1(&a[i], vl); // 加载向量a vint32m1_t vb = vle32_v_i32m1(&b[i], vl); // 加载向量b vint32m1_t vc = vadd_vv_i32m1(va, vb, vl); // 执行向量加法 vse32_v_i32m1(&c[i], vc, vl); // 存储结果向量c } }
RISC-V 向量库优化
-
循环展开 (Loop Unrolling)
- 循环展开是一种编译优化技术,通过减少循环控制开销提高性能。
- 手动循环展开可以结合向量指令进一步提升性能。
-
自动向量化
- 编译器可以自动识别并向量化循环和数据操作,以生成高效的 SIMD 代码。
- 需要确保代码中的数据访问和操作是连续且没有数据依赖的,以便编译器可以进行向量化。
-
手动向量化
- 在某些情况下,手动编写向量化代码可以获得更高的性能。
- 使用 RVV Intrinsics 或者汇编语言直接编写向量操作代码。
RISC-V SIMD 和 Unroll 优化方案
为了优化C语言程序以利用RISC-V的SIMD和Unroll技术,下面是一个详细的步骤指南,包括代码示例。
步骤1: 识别热点代码
首先,使用性能分析工具来识别程序中的热点代码段。这些热点代码通常是性能瓶颈所在,优化它们可以获得最大的性能提升。
# 使用gprof进行性能分析
gcc -O2 -pg your_program.c -o your_program
./your_program
gprof your_program gmon.out
步骤2: 重构循环
确保循环中的数据访问是连续的,这有助于提高缓存的利用率。消除循环体内的依赖,使得可以安全地应用循环展开。
原始循环
int sum = 0;
for (int i = 0; i < N; ++i) {
sum += array[i];
}
重构后的循环
int sum = 0;
for (int i = 0; i < N; i+=4) {
sum += array[i];
sum += array[i+1];
sum += array[i+2];
sum += array[i+3];
}
步骤3: 使用向量指令
使用RISC-V的向量指令集(RVV)来替换标量操作。确保数据对齐,以利用SIMD指令的性能。
使用RVV Intrinsics
#include <riscv_vector.h>
int main() {
size_t N = 1024;
int array[N], sum = 0;
vint32m1_t vec_sum = vsetvli(0, RVV_VLMAX, RVV_E32, RVV_M1);
for (int i = 0; i < N; i+=RVV_VL) {
vint32m1_t data = vle32_v_i32m1(array + i, RVV_VL);
vec_sum = vadd_vv_i32m1(vec_sum, data, RVV_VL);
}
sum = vredsum_vs_i32m1_i32(vec_sum, 0, RVV_VLMAX);
return sum;
}
步骤4: 编译器优化
启用编译器的自动向量化选项,并确保编译选项适用于RISC-V架构。
# 使用GCC编译器进行优化
gcc -O3 -march=rv64imafdc -ftree-vectorize your_program.c -o your_program
步骤5: 性能测试和调优
使用基准测试和性能分析工具来验证优化效果,并根据测试结果进一步调整代码和编译选项。
# 使用perf进行性能测试
perf stat -e task-clock,cache-misses,branches,branch-misses ./your_program
根据性能测试的结果,可能需要回到步骤2或步骤3,对循环展开的程度或向量化的使用进行调整。
注意事项
- 确保在使用向量指令之前,数据已经适当对齐。
- 循环展开的程度应该根据目标机器的寄存器数量和缓存大小来决定。
- 过度优化可能会导致代码可读性降低,需要在性能和可维护性之间找到平衡。
通过遵循上述步骤,你可以有效地利用RISC-V的SIMD和Unroll技术来优化C语言程序的性能。记得在每一步中都进行充分的测试,以确保所做的优化是有效的。
矩阵与卷积算法
本章要求
- 了解矩阵乘法和卷积算法。
- 掌握矩阵转置的概念。
- 学会通过编程实现矩阵乘法和卷积算法。
主要内容
注意
本章节为习题前置知识,而非正式课程内容,但建议先学习本章节内容再进行相关习题。
参考资料
对于矩阵乘法、卷积算法和矩阵转置算法的参考资料,以下是一些推荐的算法资料:
矩阵乘法
- Strassen算法是一种经典的矩阵乘法算法,它通过分治法将矩阵分为更小的子矩阵并递归地计算它们;矩阵乘法的朴素算法具有Θ(n^3)的时间复杂度,而Strassen算法通过递归地分割和组合子矩阵来降低时间复杂度。
卷积算法
- 实际采用的卷积算法包括但不限于VanillaConv、GroupConv、Depthwise Separable Convolution、DeformableConv、CondConv、Ghost Convolution和Involution等,它们在精度、参数量和计算量之间进行不同的取舍。
矩阵与线性代数
- 矩阵乘法是线性代数的基本运算,它可以用来表示和操作向量、矩阵、张量等数学对象。矩阵的加法、减法、乘法、除法、转置、行列式、特征值、特征向量等运算都是线性代数的基本概念。
算法流程
- 确定输入矩阵的维度。
- 确定输出矩阵的维度。
- 按照输出矩阵的维度,将输入矩阵的行向量依次与输出矩阵的列向量进行矩阵乘法运算,得到输出矩阵的相应元素。
- 输出矩阵的元素即为输入矩阵与输出矩阵的乘积。
伪代码
- 输入矩阵 A 的维度为 m * n,输出矩阵 B 的维度为 p * q。
- 对于 i = 1 to p,j = 1 to q,执行以下操作:
- 对于 k = 1 to n,执行以下操作:
- 计算 A(i, k) * B(k, j) 并将结果累加到 C(i, j) 中。
- 输出矩阵 C 的元素即为输入矩阵 A 和输出矩阵 B 的卷积。
- 对于 k = 1 to n,执行以下操作:
示例代码(C语言)
// 假设我们有两个矩阵A和B,它们的尺寸分别为 m x n 和 n x p,矩阵C是结果矩阵,尺寸为 m x p。
void matrix_multiply(int m, int n, int p, double A[m][n], double B[n][p], double C[m][p]) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < p; j++) {
C[i][j] = 0;
for (int k = 0; k < n; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
卷积算法
卷积算法是一种在信号处理、图像处理、机器学习等领域广泛使用的数学运算。它涉及到两个函数的卷积,通常用来分析一个信号或函数与另一个信号或函数的相似度。在深度学习中,卷积神经网络(CNN)就是基于卷积算法构建的。
The convolution of two functions \( f(t) \) and \( g(t) \), denoted as \( (f * g)(t) \), is defined as:
\[ (f * g)(t) = \int_{-\infty}^{\infty} f(\tau) g(t - \tau) \, d\tau \]
其中,τ是积分变量,t是时间或空间的坐标。
在离散情况下,卷积定义为:
\[ (f * g)(n) = \sum_{m=-\infty}^{\infty} f(m) g(n - m) \]
这里的f(m)和g(m)是离散信号的值。卷积的应用
信号处理:用于滤波、平滑、特征提取等。 图像处理:用于边缘检测、图像平滑、特征提取等。 机器学习:在卷积神经网络中,卷积层通过卷积操作提取输入数据的特征。
卷积算法流程
- 确定卷积核:选择或学习一个卷积核(滤波器)。
- 卷积核中心定位:将卷积核中心对齐到输入数据的第一个位置。
- 元素乘积:计算卷积核和输入数据对应位置的元素乘积。
- 求和:将上一步得到的乘积求和,得到输出特征图的一个元素。
- 滑动卷积核:将卷积核向右滑动一个元素宽度,重复步骤3和4。
资料
示例代码(C语言)
// 假设我们有一个输入矩阵 input 和一个卷积核 kernel,我们需要计算输出矩阵 output。
void convolution2D(int inputRows, int inputCols, double input[inputRows][inputCols],
int kernelRows, int kernelCols, double kernel[kernelRows][kernelCols],
double output[inputRows][inputCols]) {
int kernelCenterX = kernelCols / 2;
int kernelCenterY = kernelRows / 2;
for (int i = 0; i < inputRows; ++i) {
for (int j = 0; j < inputCols; ++j) {
output[i][j] = 0; // 初始化输出矩阵
for (int m = 0; m < kernelRows; ++m) {
for (int n = 0; n < kernelCols; ++n) {
int ii = i + (m - kernelCenterY);
int jj = j + (n - kernelCenterX);
// 检查是否越界
if (ii >= 0 && ii < inputRows && jj >= 0 && jj < inputCols) {
output[i][j] += input[ii][jj] * kernel[m][n];
}
}
}
}
}
}
矩阵转置
矩阵转置是指矩阵的行列互换,记作$A^T$,定义为:
\[ A^T = [a_{ij}]_{m\times n} = \left[ \begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{array} \right] \]
即为: 对每一个i,j,将矩阵A的第i行的元素与第j列的元素进行交换。
示例代码(C语言)
// 假设我们有一个矩阵 A,我们需要计算它的转置矩阵。
void transpose(int m, int n, double A[m][n], double AT[n][m]) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
AT[j][i] = A[i][j];
}
}
}
原地转置
void transpose(int m, int n, double A[m][n]) {
for (int i = 0; i < m; i++) {
for (int j = i + 1; j < n; j++) {
double temp = A[i][j];
A[i][j] = A[j][i];
A[j][i] = temp;
}
}
}
Linux内核模块
本章要求
- 了解Linux内核模块的概念和用法。
- 掌握编写一个简单内核模块的方法。
- 了解内核模块参数的传递方式。
- 学会利用内核模块创建一个虚拟字符设备。
- 了解如何通过数组参数传递给内核模块。
主要内容
注意
本章节为习题前置知识,而非正式课程内容,但建议先学习本章节内容再进行相关习题。
前提条件
要跟随本教程,您需要具备以下前提条件:
- 熟练掌握C编程
- 基本的Linux命令行知识
- 已设置好Linux开发环境(例如,运行Linux发行版并安装了
make和gcc)
本章简介
本教程为编写 Linux 内核模块提供了一个起点。它涵盖了模块参数传递、创建虚拟字符设备、启动定时器以及使用简单的文件操作。对于更高级的主题,请参考《Linux 内核模块编程指南》和其他内核开发资源。
参考文献
编写一个简单的内核模块
从一个简单的“Hello, World!”内核模块开始,了解模块编程的基础。
示例
#include <linux/module.h> // Needed by all modules
#include <linux/kernel.h> // Needed for KERN_INFO
#include <linux/init.h> // Needed for macros
static int __init hello_init(void)
{
printk(KERN_INFO "Hello, World!\n");
return 0;
}
static void __exit hello_exit(void)
{
printk(KERN_INFO "Goodbye, World!\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A simple Hello World module");
编译与加载模块
- 在目录中编写
Makefile:obj-m += hello_module.o all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
注意:之后其他章节均有类似此示例的Makefile,故省略不写,Makefile中
obj-m变量的值应与模块名一致。
-
编译模块:
make -
加载模块:
sudo insmod hello_module.ko -
查看模块加载日志:
dmesg | tail -
卸载模块:
sudo rmmod hello_module
内核模块传参
示例
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/moduleparam.h>
static int param_var = 0;
module_param(param_var, int, S_IRUGO);
MODULE_PARM_DESC(param_var, "An integer");
static int __init param_init(void)
{
printk(KERN_INFO "param_var: %d\n", param_var);
return 0;
}
static void __exit param_exit(void)
{
printk(KERN_INFO "Exiting param_module\n");
}
module_init(param_init);
module_exit(param_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A module with parameter passing");
加载模块并传入参数
sudo insmod param_module.ko param_var=42
dmesg | tail
数组传参
Linux 内核模块可以接受数组作为参数,这对于配置和自定义模块行为非常有用。下面我们展示如何实现这一点。
示例
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/moduleparam.h>
#define MAX_ARRAY_SIZE 5
// Define an array and a variable to hold the array size
static int array[MAX_ARRAY_SIZE];
static int arr_argc = 0;
// Define the module parameters
module_param_array(array, int, &arr_argc, 0000);
MODULE_PARM_DESC(array, "An integer array");
static int __init array_param_init(void)
{
int i;
printk(KERN_INFO "Array parameter module initialized with %d elements\n", arr_argc);
for (i = 0; i < arr_argc; i++)
{
printk(KERN_INFO "array[%d] = %d\n", i, array[i]);
}
return 0;
}
static void __exit array_param_exit(void)
{
printk(KERN_INFO "Exiting array parameter module\n");
}
module_init(array_param_init);
module_exit(array_param_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A module with array parameter passing");
加载模块并传递数组参数:
```bash
sudo insmod array_param_module.ko array=1,2,3,4,5
```
总结
通过这种方式,可以向内核模块传递数组参数,从而使模块更加灵活和可配置。这对于需要动态传递多个参数的情况非常有用。
创建虚拟字符设备
虚拟字符设备通过文件操作与用户空间应用程序交互。
示例代码
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/uaccess.h> // copy_to_user, copy_from_user
#include <linux/cdev.h>
#define DEVICE_NAME "vchardev"
#define BUF_LEN 80
static int major;
static char message[BUF_LEN];
static struct class *vchardev_class = NULL;
static struct device *vchardev_device = NULL;
static int dev_open(struct inode *inode, struct file *file)
{
printk(KERN_INFO "vchardev: device opened\n");
return 0;
}
static int dev_release(struct inode *inode, struct file *file)
{
printk(KERN_INFO "vchardev: device closed\n");
return 0;
}
static ssize_t dev_read(struct file *file, char __user *buffer, size_t len, loff_t *offset)
{
int bytes_read = 0;
if (*message == 0)
return 0;
while (len && *message)
{
put_user(*(message++), buffer++);
len--;
bytes_read++;
}
printk(KERN_INFO "vchardev: read %d bytes\n", bytes_read);
return bytes_read;
}
static ssize_t dev_write(struct file *file, const char __user *buffer, size_t len, loff_t *offset)
{
int i;
for (i = 0; i < len && i < BUF_LEN - 1; i++)
get_user(message[i], buffer + i);
message[i] = '\0';
printk(KERN_INFO "vchardev: received %zu characters from user\n", len);
return len;
}
static struct file_operations fops = {
.open = dev_open,
.read = dev_read,
.write = dev_write,
.release = dev_release,
};
static int __init vchardev_init(void)
{
major = register_chrdev(0, DEVICE_NAME, &fops);
if (major < 0)
{
printk(KERN_ALERT "vchardev failed to register a major number\n");
return major;
}
printk(KERN_INFO "vchardev: registered with major number %d\n", major);
vchardev_class = class_create(THIS_MODULE, DEVICE_NAME);
if (IS_ERR(vchardev_class))
{
unregister_chrdev(major, DEVICE_NAME);
printk(KERN_ALERT "Failed to register device class\n");
return PTR_ERR(vchardev_class);
}
printk(KERN_INFO "vchardev: device class registered\n");
vchardev_device = device_create(vchardev_class, NULL, MKDEV(major, 0), NULL, DEVICE_NAME);
if (IS_ERR(vchardev_device))
{
class_destroy(vchardev_class);
unregister_chrdev(major, DEVICE_NAME);
printk(KERN_ALERT "Failed to create the device\n");
return PTR_ERR(vchardev_device);
}
printk(KERN_INFO "vchardev: device created\n");
return 0;
}
static void __exit vchardev_exit(void)
{
device_destroy(vchardev_class, MKDEV(major, 0));
class_unregister(vchardev_class);
class_destroy(vchardev_class);
unregister_chrdev(major, DEVICE_NAME);
printk(KERN_INFO "vchardev: module unloaded\n");
}
module_init(vchardev_init);
module_exit(vchardev_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A simple virtual character device");
编译运行调试
编译代码:
$ make
加载模块:
$ insmod vchardev.ko
查看模块信息:
$ lsmod | grep vchardev
vchardev 16384 0
创建设备文件:
$ mknod /dev/vchardev c 254 0
查看设备文件信息:
$ ls -l /dev/vchardev
crw-rw-rw- 1 root root 254, 0 May 20 10:20 /dev/vchardev
打开设备文件:
$ cat /dev/vchardev
向设备文件写入数据:
$ echo "Hello, world!" > /dev/vchardev
从设备文件读取数据:
$ cat /dev/vchardev
Hello, world!
卸载模块:
$ rmmod vchardev
实现计时器
计时器对于在内核空间中处理定时操作至关重要。
示例
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/timer.h>
static struct timer_list my_timer;
void timer_callback(struct timer_list *t)
{
printk(KERN_INFO "Timer expired and callback executed\n");
}
static int __init timer_init(void)
{
printk(KERN_INFO "Initializing Timer Module\n");
timer_setup(&my_timer, timer_callback, 0);
mod_timer(&my_timer, jiffies + msecs_to_jiffies(2000)); // 2 seconds
return 0;
}
static void __exit timer_exit(void)
{
del_timer(&my_timer);
printk(KERN_INFO "Timer Module Unloaded\n");
}
module_init(timer_init);
module_exit(timer_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A simple timer module");
编译运行调试
加载模块:
sudo insmod timer.ko
卸载模块:
sudo rmmod timer
查看日志:
dmesg
在日志中可以看到打印的时间信息。
实现简单的文件操作函数
filp_open函数及示例
filp_open 用于在内核空间打开一个文件。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/file.h>
#include <linux/slab.h>
static int __init filp_open_example_init(void)
{
struct file *f;
char buf[128];
mm_segment_t fs;
loff_t pos = 0;
printk(KERN_INFO "Opening file from kernel space\n");
f = filp_open("/etc/hostname", O_RDONLY, 0);
if (IS_ERR(f))
{
printk(KERN_ALERT "Failed to open file\n");
return PTR_ERR(f);
}
fs = get_fs();
set_fs(KERNEL_DS);
vfs_read(f, buf, sizeof(buf), &pos);
set_fs(fs);
printk(KERN_INFO "File content: %s\n", buf);
filp_close(f, NULL);
return 0;
}
static void __exit filp_open_example_exit(void)
{
printk(KERN_INFO "Unloading filp_open_example module\n");
}
module_init(filp_open_example_init);
module_exit(filp_open_example_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A module demonstrating filp_open");
加载与调试
编译并加载模块:
$ make
$ sudo insmod filp_open_example.ko
运行结果:
[ 26.313563] Opening file from kernel space
[ 26.313602] File content: localhost
[ 26.313605] Unloading filp_open_example module
Linux系统编程基础
本章要求
- 了解Linux系统编程的基本概念,包括进程、线程、内存管理、文件系统接口等。
- 掌握Linux系统编程的基本技术,包括获取主机名、设置程序内存上限、使用
fork创建子进程、通过管道进行进程间通讯等。 - 能够编写简单的Linux系统编程程序。
注意
本章节为习题前置知识,而非正式课程内容,但建议先学习本章节内容再进行相关习题。
介绍
Linux系统编程涉及使用C语言与操作系统进行直接交互。本文将详细介绍一些基本的Linux系统编程技术,并通过示例代码展示如何获取主机名、设置程序内存上限、使用fork创建子进程,以及通过管道进行进程间通讯。
获取主机名
gethostname函数
gethostname函数用于获取当前主机的名称。它的原型如下:
#include <unistd.h>
int gethostname(char *name, size_t len);
示例代码
#include <stdio.h>
#include <unistd.h>
#include <limits.h>
int main() {
char hostname[HOST_NAME_MAX];
if (gethostname(hostname, sizeof(hostname)) == -1) {
perror("gethostname");
return 1;
}
printf("Hostname: %s\n", hostname);
return 0;
}
使用rlimit设置程序内存上限
setrlimit函数
setrlimit函数用于设置进程的资源限制。它的原型如下:
#include <sys/resource.h>
int setrlimit(int resource, const struct rlimit *rlim);
示例代码
#include <stdio.h>
#include <sys/resource.h>
int main() {
struct rlimit rl;
// 设置程序的内存上限为128MB
rl.rlim_cur = 128 * 1024 * 1024;
rl.rlim_max = 128 * 1024 * 1024;
if (setrlimit(RLIMIT_AS, &rl) == -1) {
perror("setrlimit");
return 1;
}
printf("Memory limit set to 128MB\n");
return 0;
}
fork函数创建子进程
fork函数
fork函数用于创建一个子进程。它的原型如下:
#include <unistd.h>
pid_t fork(void);
示例代码
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid == -1) {
perror("fork");
return 1;
} else if (pid == 0) {
// 子进程
printf("Hello from the child process!\n");
} else {
// 父进程
printf("Hello from the parent process!\n");
}
return 0;
}
管道与进程间通讯
pipe函数
pipe函数用于创建一个管道,管道是进程间通讯的一种方式。它的原型如下:
#include <unistd.h>
int pipe(int pipefd[2]);
示例代码
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
int pipefd[2];
char buffer[128];
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
pid_t pid = fork();
if (pid == -1) {
perror("fork");
return 1;
} else if (pid == 0) {
// 子进程
close(pipefd[0]); // 关闭读端
char message[] = "Hello from the child process!";
write(pipefd[1], message, strlen(message));
close(pipefd[1]); // 关闭写端
} else {
// 父进程
close(pipefd[1]); // 关闭写端
read(pipefd[0], buffer, sizeof(buffer));
printf("Parent received: %s\n", buffer);
close(pipefd[0]); // 关闭读端
}
return 0;
}
学习资料
学习Linux系统编程的相关资料和教程非常丰富,以下是一些推荐的资源:
书籍
-
《UNIX环境高级编程》(Advanced Programming in the UNIX Environment) - 作者:W. Richard Stevens
- 这本书被誉为UNIX编程的经典之作,详细介绍了UNIX系统编程的各个方面,是深入学习Linux编程的必备书籍。
-
《Linux系统编程》(Linux System Programming) - 作者:Robert Love
- 本书专门介绍了Linux系统编程的基础和高级主题,涵盖了文件I/O、进程控制、线程和同步、网络编程等内容。
-
《深入理解Linux内核》(Understanding the Linux Kernel) - 作者:Daniel P. Bovet, Marco Cesati
- 这本书深入解析了Linux内核的各个子系统和模块,对理解Linux系统的工作原理非常有帮助。
在线教程和文档
-
The Linux Programming Interface - 作者:Michael Kerrisk
- 该书的官方网站提供了部分章节的在线阅读和示例代码,详细讲解了Linux编程接口。
-
- 官方文档详细介绍了GNU C库中的各个函数和数据结构,是查阅具体函数用法的权威资料。
-
Linux Manual Pages (man pages)
- Linux系统自带的手册页提供了大量函数和命令的使用说明,使用
man命令可以方便地查阅。 - 例如,
man 2 fork可以查看fork系统调用的详细信息。
- Linux系统自带的手册页提供了大量函数和命令的使用说明,使用
在线课程
-
Coursera: "Operating Systems and You: Becoming a Power User"
- 这门课程由谷歌提供,介绍了Linux操作系统的基本使用和系统编程的基本概念。
-
Udacity: "Linux System Programming"
- 这门课程提供了Linux系统编程的入门知识,适合初学者学习。
社区和论坛
-
- Stack Overflow是一个大型编程问答社区,里面有大量关于Linux系统编程的问答,搜索具体问题时可以找到许多有用的答案。
-
- Reddit的Linux板块讨论Linux系统相关的各种话题,包括系统编程,里面有很多经验丰富的用户可以提供帮助。
实验和实践
- Linux From Scratch (LFS)
- 通过从零开始构建一个Linux系统,可以深入理解Linux的各个组件和编程接口。
RISC-V架构内联汇编
本章要求
- 了解RISC-V指令集的基本知识。
- 了解RISC-V架构的特点,以及如何在C语言中使用内联汇编。
- 掌握C语言中常见的控制结构的汇编表示方法。
主要内容
注意
本章节为习题前置知识,而非正式课程内容,但建议先学习本章节内容再进行相关习题。
本章简介
通过本教程,你将了解如何在RISC-V架构上使用内联汇编,并掌握将C语言中的控制结构转换为汇编代码的方法。希望这些内容对你在实际编程中有所帮助。
参考资料
- RISC-V 官方文档
- GCC 内联汇编指南
- RISC-V 汇编教程
- Learn RISC-V Assembly
- 《RISC-V汇编语言程序设计》
- 《嵌入式系统与RISC-V架构》
RISC-V架构简介
RISC-V(发音为“risk-five”)是一个开源的指令集架构(ISA),它由加利福尼亚大学伯克利分校开发。RISC-V 的设计原则是简洁、模块化和可扩展,使其在研究、教育和商业领域都得到了广泛应用。
RISC-V 的主要特点
-
开源与自由:RISC-V 是一个开放标准的 ISA,任何人都可以免费使用、修改和发布。这种开源特性使得 RISC-V 在学术研究和商业应用中具有很大的吸引力。
-
简洁性:RISC-V 的设计强调简洁,采用了精简指令集计算(RISC)原则。这使得 RISC-V 指令集相比于复杂指令集计算(CISC)如 x86 更加简单和高效。
-
模块化:RISC-V 采用模块化设计,不同的应用可以选择不同的扩展。基础的 RISC-V ISA 被称为 RV32I(32位)或 RV64I(64位),并可以通过添加扩展模块(如浮点、原子操作、多线程等)来增强功能。
-
可扩展性:RISC-V 支持从嵌入式系统到高性能计算的各种应用场景。其指令集架构可以扩展以支持特定领域的需求,比如专门用于机器学习加速的扩展。
RISC-V 基础指令集
RISC-V 的基础指令集包括以下几个部分:
- 整数计算指令(RV32I/RV64I):包括基本的算术、逻辑、移位和比较指令。
- 控制流指令:包括条件分支、无条件跳转和函数调用/返回指令。
- 内存访问指令:包括加载和存储指令,用于数据在寄存器和内存之间的传输。
RISC-V 的扩展
- M 扩展(乘法和除法):增加了整数乘法和除法指令。
- A 扩展(原子操作):支持原子读-修改-写指令,用于多线程同步。
- F 和 D 扩展(浮点数):增加了单精度(F)和双精度(D)浮点运算指令。
- C 扩展(压缩指令):通过使用更短的指令编码来减少程序的代码大小。
- V 扩展(向量操作):支持向量化操作,以加速数据并行计算。
RISC-V 的应用
RISC-V 的灵活性和开放性使得它在多种领域中得到了应用,包括:
- 嵌入式系统:由于其简洁和高效,RISC-V 非常适合低功耗的嵌入式设备。
- 物联网(IoT):开源的特点使得 RISC-V 可以广泛应用于各种物联网设备中。
- 高性能计算:通过添加特定的扩展模块,RISC-V 也可以应用于高性能计算领域。
- 教育和研究:RISC-V 的开放性和模块化设计使其成为教学和研究的理想平台。
RISC-V基础指令集
本集训营用的最多的指令集是RV64I基础,它包含了处理器指令集最核心的部分:整数计算、控制流和内存访问指令,指令简单明了,适合快速掌握。
下面是对 RV64I 基础指令集的详细介绍。
寄存器
x0-x31:32个整数寄存器。f0-f31:32个浮点寄存器。pc:程序计数器。sp:堆栈指针。ra:返回地址寄存器。
指令格式
指令格式如下:
opcode rd, rs1, rs2 [, imm]
opcode:指令的操作码。rd:目标寄存器。rs1:源寄存器1。rs2:源寄存器2。imm:立即数。
指令集
RV32I 基础指令集
RV32I 基础指令集包含了整数计算、控制流和内存访问指令。
- 整数计算指令:
ADD,SUB,ADDI,AND,OR,XOR,ANDI,SLL,SRL,SRA,SLT,SLTU,SLTI - 控制流指令:
BEQ,BNE,BLT,BGE,JAL,JALR - 内存访问指令:
LW,LH,LHU,LB,LBU,SW,SH,SB
整数计算指令
算术指令
- ADD: 将两个寄存器的值相加,结果存储在目标寄存器中。
ADD rd, rs1, rs2 # rd = rs1 + rs2 - SUB: 将一个寄存器的值从另一个寄存器的值中减去,结果存储在目标寄存器中。
SUB rd, rs1, rs2 # rd = rs1 - rs2 - ADDI: 将一个立即数与寄存器的值相加,结果存储在目标寄存器中。
ADDI rd, rs1, imm # rd = rs1 + imm
逻辑指令
- AND: 对两个寄存器的值执行按位与操作,结果存储在目标寄存器中。
AND rd, rs1, rs2 # rd = rs1 & rs2 - OR: 对两个寄存器的值执行按位或操作,结果存储在目标寄存器中。
OR rd, rs1, rs2 # rd = rs1 | rs2 - XOR: 对两个寄存器的值执行按位异或操作,结果存储在目标寄存器中。
XOR rd, rs1, rs2 # rd = rs1 ^ rs2 - ANDI: 将寄存器的值与一个立即数进行按位与操作,结果存储在目标寄存器中。
ANDI rd, rs1, imm # rd = rs1 & imm
移位指令
- SLL: 将寄存器的值左移指定的位数,结果存储在目标寄存器中。
SLL rd, rs1, rs2 # rd = rs1 << rs2 - SRL: 将寄存器的值右移指定的位数,结果存储在目标寄存器中(逻辑右移)。
SRL rd, rs1, rs2 # rd = rs1 >> rs2 - SRA: 将寄存器的值右移指定的位数,结果存储在目标寄存器中(算术右移)。
SRA rd, rs1, rs2 # rd = rs1 >> rs2 (arithmetic)
比较指令
- SLT: 如果第一个寄存器的值小于第二个寄存器的值,则目标寄存器设置为1,否则设置为0(有符号比较)。
SLT rd, rs1, rs2 # rd = (rs1 < rs2) - SLTU: 如果第一个寄存器的值小于第二个寄存器的值,则目标寄存器设置为1,否则设置为0(无符号比较)。
SLTU rd, rs1, rs2 # rd = (rs1 < rs2) (unsigned) - SLTI: 如果寄存器的值小于立即数,则目标寄存器设置为1,否则设置为0(有符号比较)。
SLTI rd, rs1, imm # rd = (rs1 < imm)
控制流指令
条件分支指令
- BEQ: 如果两个寄存器的值相等,则跳转到目标地址。
BEQ rs1, rs2, offset # if (rs1 == rs2) PC += offset - BNE: 如果两个寄存器的值不相等,则跳转到目标地址。
BNE rs1, rs2, offset # if (rs1 != rs2) PC += offset - BLT: 如果第一个寄存器的值小于第二个寄存器的值,则跳转到目标地址(有符号比较)。
BLT rs1, rs2, offset # if (rs1 < rs2) PC += offset - BGE: 如果第一个寄存器的值大于或等于第二个寄存器的值,则跳转到目标地址(有符号比较)。
BGE rs1, rs2, offset # if (rs1 >= rs2) PC += offset
无条件跳转指令
- JAL: 跳转到目标地址,并将返回地址存储在目标寄存器中。
JAL rd, offset # rd = PC + 4; PC += offset - JALR: 跳转到由寄存器和立即数计算出的地址,并将返回地址存储在目标寄存器中。
JALR rd, rs1, offset # rd = PC + 4; PC = (rs1 + offset) & ~1
内存访问指令
加载指令
- LW: 从内存中加载一个字(32位)到目标寄存器。
LW rd, offset(rs1) # rd = *(rs1 + offset) - LH: 从内存中加载一个半字(16位)到目标寄存器,并进行符号扩展。
LH rd, offset(rs1) # rd = *(int16_t *)(rs1 + offset) - LHU: 从内存中加载一个半字(16位)到目标寄存器,并进行零扩展。
LHU rd, offset(rs1) # rd = *(uint16_t *)(rs1 + offset) - LB: 从内存中加载一个字节(8位)到目标寄存器,并进行符号扩展。
LB rd, offset(rs1) # rd = *(int8_t *)(rs1 + offset) - LBU: 从内存中加载一个字节(8位)到目标寄存器,并进行零扩展。
LBU rd, offset(rs1) # rd = *(uint8_t *)(rs1 + offset)
存储指令
- SW: 将一个字(32位)从源寄存器存储到内存中。
SW rs2, offset(rs1) # *(rs1 + offset) = rs2 - SH: 将一个半字(16位)从源寄存器存储到内存中。
SH rs2, offset(rs1) # *(int16_t *)(rs1 + offset) = rs2 - SB: 将一个字节(8位)从源寄存器存储到内存中。
SB rs2, offset(rs1) # *(int8_t *)(rs1 + offset) = rs2
这些指令构成了 RISC-V 基础指令集的重要部分,为各种计算和控制流操作提供了必要的功能。
控制结构的汇编表示方法
C语言与汇编往往呈现一一对应关系,但控制结构的汇编表示方法却有所不同。本节将介绍C语言控制结构的汇编表示方法,以大家最为熟悉的C语言结构——循环、分支、跳转为例,介绍如何用汇编语言表示这些控制结构。
内联汇编语法
在GCC编译器中,内联汇编使用asm关键字。以下是一个基本的内联汇编语法示例:
int result;
asm("add %0, %1, %2" : "=r" (result) : "r" (a), "r" (b));
"add %0, %1, %2":汇编指令模板。: "=r" (result):输出操作数,=r表示输出到寄存器。: "r" (a), "r" (b):输入操作数,r表示从寄存器读取。
在上面的示例中,result变量的值等于a和b的和。
控制结构的内联汇编表示
while循环
int i = 0;
while (i < 10) {
// 循环体
i++;
}
等价的内联汇编:
int i = 0;
asm volatile (
"loop_start: \n\t"
" blt %[i], %[max], loop_body \n\t"
" j loop_end \n\t"
"loop_body: \n\t"
" addi %[i], %[i], 1 \n\t"
" j loop_start \n\t"
"loop_end: \n\t"
: [i] "+r" (i)
: [max] "r" (10)
: "cc"
);
if-else语句
int a = 5, b = 10;
if (a < b) {
// 真分支
} else {
// 假分支
}
等价的内联汇编:
int a = 5, b = 10;
asm volatile (
" blt %[a], %[b], if_true \n\t"
" j else_branch \n\t"
"if_true: \n\t"
// 真分支代码
" j end_if \n\t"
"else_branch: \n\t"
// 假分支代码
"end_if: \n\t"
:
: [a] "r" (a), [b] "r" (b)
: "cc"
);
do-while循环
int i = 0;
do {
// 循环体
i++;
} while (i < 10);
等价的内联汇编:
int i = 0;
asm volatile (
"do_start: \n\t"
" addi %[i], %[i], 1 \n\t"
" blt %[i], %[max], do_start \n\t"
: [i] "+r" (i)
: [max] "r" (10)
: "cc"
);
switch语句
int val = 2;
switch (val) {
case 1:
// case 1代码
break;
case 2:
// case 2代码
break;
default:
// 默认代码
break;
}
等价的内联汇编:
int val = 2;
asm volatile (
" li t0, 1 \n\t"
" beq %[val], t0, case1 \n\t"
" li t0, 2 \n\t"
" beq %[val], t0, case2 \n\t"
" j default_case \n\t"
"case1: \n\t"
// case 1代码
" j end_switch \n\t"
"case2: \n\t"
// case 2代码
" j end_switch \n\t"
"default_case: \n\t"
// 默认代码
"end_switch: \n\t"
:
: [val] "r" (val)
: "t0", "cc"
);
continue与break
在循环中使用continue和break:
for (int i = 0; i < 10; i++) {
if (i == 5) continue;
if (i == 8) break;
// 循环体
}
等价的内联汇编:
int i = 0;
asm volatile (
"for_start: \n\t"
" bge %[i], %[max], for_end \n\t"
" li t0, 5 \n\t"
" beq %[i], t0, continue_loop \n\t"
" li t0, 8 \n\t"
" beq %[i], t0, for_end \n\t"
// 循环体代码
"continue_loop: \n\t"
" addi %[i], %[i], 1 \n\t"
" j for_start \n\t"
"for_end: \n\t"
: [i] "+r" (i)
: [max] "r" (10)
: "t0", "cc"
);
操作系统常用算法
本章要求
- 了解操作系统中常用的页面置换算法。
- 掌握FIFO页面置换算法的实现。
- 掌握LRU页面置换算法的实现。
- 理解并实现时间片轮转调度算法。
主要内容
注意
本章节为习题前置知识,而非正式课程内容,但建议先学习本章节内容再进行相关习题。
参考文献
页面置换算法
- Tanenbaum, A. S., & Bos, H. (2014). Operating Systems: Design and Implementation. - 这本书详细介绍了操作系统的设计与实现,包括页面置换算法的原理和实现。
- Silberschatz, A., Galvin, P. B., & Gagne, G. (2012). Operating System Concepts. - 作为操作系统的经典教材,涵盖了页面置换算法的基本概念和实现方法。
- Stallings, W. (2014). Operating Systems: Internals and Design Principles. - 这本书提供了操作系统的内部机制和设计原则的深入讨论,包括页面置换策略。
FIFO页面置换算法
- FIFO Page Replacement Algorithm. - 通常作为操作系统内存管理章节的一部分,在上述推荐的书籍中有所介绍。
LRU页面置换算法
- Belady, L. A. (1966). A study of replacement algorithms for a virtual storage computer. - 这是LRU算法的原始论文,详细介绍了算法的设计和评估。
- LRU Cache Implementation. - 可在多个算法和数据结构的在线资源中找到,例如GeeksforGeeks或LeetCode。
时间片轮转调度算法
- Time Slice Scheduling. - 通常包含在操作系统的调度章节中,上述推荐的书籍有详细的讨论和示例。
- Kanetkar, Y. (2012). Unix System Programming. - 虽然主要关注UNIX系统编程,但也提供了对时间片轮转调度算法的实用视角。
在线资源和教程
- Operating System Tutorials on GeeksforGeeks. - 提供了操作系统概念的详细教程,包括页面置换和调度算法。
- MIT OpenCourseWare. - 麻省理工学院的公开课资源,可能包含操作系统课程的讲义和实验,涵盖本章要求的算法。
FIFO 页面置换算法
原理
FIFO(First-In-First-Out)页面置换算法是一种最简单的页面置换算法。它将最早加载进内存的页面置换出去。换句话说,当需要一个新的页面时,最先进入内存的页面将被移除。
函数实现
以下是FIFO页面置换算法的实现:
#include <stdio.h>
#include <string.h>
#define MAX_FRAMES 10
void fifo_page_replacement(char *queue_frames, int num_frames) {
int frames[MAX_FRAMES];
int front = 0;
int rear = 0;
int size = 0;
int page_faults = 0;
for (int i = 0; i < num_frames; i++) {
frames[i] = -1; // 初始化页框为空
}
for (int i = 0; i < strlen(queue_frames); i++) {
int page = queue_frames[i] - '0';
int found = 0;
// 检查页面是否已经在页框中
for (int j = 0; j < size; j++) {
if (frames[j] == page) {
found = 1;
break;
}
}
// 页面不在页框中,需要置换
if (!found) {
page_faults++;
frames[rear] = page;
rear = (rear + 1) % num_frames;
// 如果页框未满,增加当前大小
if (size < num_frames) {
size++;
}
}
// 打印当前页框状态
printf("Page %d: [", page);
for (int j = 0; j < size; j++) {
printf("%d", frames[j]);
if (j < size - 1) {
printf(" ");
}
}
printf("]\n");
}
printf("Total page faults: %d\n", page_faults);
}
int main() {
char queue_frames[] = "70120304230321201701";
int num_frames = 3;
fifo_page_replacement(queue_frames, num_frames);
return 0;
}
LRU 页面置换算法
原理
LRU(Least Recently Used)页面置换算法根据页面最近使用的情况来决定置换哪一个页面。具体来说,它将最久未被使用的页面置换出去。
函数实现
以下是LRU页面置换算法的实现:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_FRAMES 100
/**
* 函数:模拟LRU页面置换算法。
*
* @param queue_frames 一个字符串,表示页面访问序列。
* 字符串中的每个字符是一个数字,表示一个页面号。
* @param num_frames 页框的数量,表示物理内存中可用的页框数。
*/
void lru_page_replacement(char *queue_frames, int num_frames) {
int frames[MAX_FRAMES];
int counter[MAX_FRAMES];
int time = 0;
int page_faults = 0;
for (int i = 0; i < num_frames; i++) {
frames[i] = -1; // 初始化页框为空
counter[i] = 0; // 初始化计数器
}
for (int i = 0; i < strlen(queue_frames); i++) {
int page = queue_frames[i] - '0';
int found = 0;
// 检查页面是否已经在页框中
for (int j = 0; j < num_frames; j++) {
if (frames[j] == page) {
found = 1;
counter[j] = ++time; // 更新页面使用时间
break;
}
}
// 页面不在页框中,需要置换
if (!found) {
page_faults++;
int lru_index = 0;
int lru_time = counter[0];
// 找到最久未使用的页面
for (int j = 1; j < num_frames; j++) {
if (counter[j] < lru_time) {
lru_time = counter[j];
lru_index = j;
}
}
frames[lru_index] = page;
counter[lru_index] = ++time;
// 打印当前页框状态
printf("Page %d: [", page);
for (int j = 0; j < num_frames; j++) {
printf("%d", frames[j]);
if (j < num_frames - 1) {
printf(" ");
}
}
printf("]\n");
}
}
printf("Total page faults: %d\n", page_faults);
}
int main() {
char queue_frames[] = "70120304230321201701";
int num_frames = 3;
lru_page_replacement(queue_frames, num_frames);
return 0;
}
这两个函数分别实现了FIFO和LRU页面置换算法。在每个函数中,queue_frames是页面访问序列,num_frames是可用的页框数。每次访问一个页面时,函数会检查该页面是否在页框中。如果不在,则需要置换一个页面。FIFO算法总是置换最早进入内存的页面,而LRU算法则置换最久未使用的页面。
模拟时间片轮转调度算法
原理
时间片轮转(Round Robin, RR)是一种广泛使用的进程调度算法。其核心思想是将CPU时间划分成固定长度的时间片(time slices),并按顺序将这些时间片分配给就绪队列中的每个进程。每个进程在其时间片内运行,当时间片用完时,如果进程尚未完成,则将其置于就绪队列的末尾,等待下一轮调度。这样可以确保所有进程都能公平地获得CPU资源。
进程结构体
进程结构体包含以下字段:
pid:进程ID,用于标识进程。arrival_time:到达时间,进程进入系统的时间。burst_time:运行时间,进程需要的总CPU时间。remaining_time:剩余运行时间,用于记录进程还需要多少时间完成。completion_time:完成时间,进程完成执行的时间。turnaround_time:周转时间,进程从到达至完成所经历的总时间(完成时间 - 到达时间)。waiting_time:等待时间,进程在就绪队列中等待的时间(周转时间 - 运行时间)。
输入数据
时间片长度:4 个时间单位。
进程数量:4 个进程。
每个进程的到达时间和运行时间如下表所示:
| 进程ID | 到达时间 | 运行时间 |
|---|---|---|
| P1 | 0 | 10 |
| P2 | 1 | 6 |
| P3 | 2 | 8 |
| P4 | 3 | 4 |
计算方法
模拟时间片轮转调度算法,并计算每个进程的完成时间、周转时间和等待时间。
#include <stdio.h>
typedef struct {
int pid; // 进程ID
int arrival_time; // 到达时间
int burst_time; // 运行时间
int remaining_time; // 剩余运行时间
int completion_time; // 完成时间
int turnaround_time; // 周转时间
int waiting_time; // 等待时间
} Process;
#define TIME_SLICE 4
#define NUM_PROCESSES 4
void calculateTime(Process processes[], int n) {
int time = 0;
int completed = 0;
while (completed < n) {
for (int i = 0; i < n; i++) {
if (processes[i].arrival_time <= time && processes[i].remaining_time > 0) {
if (processes[i].remaining_time <= TIME_SLICE) {
time += processes[i].remaining_time;
processes[i].remaining_time = 0;
processes[i].completion_time = time;
processes[i].turnaround_time = processes[i].completion_time - processes[i].arrival_time;
processes[i].waiting_time = processes[i].turnaround_time - processes[i].burst_time;
completed++;
} else {
time += TIME_SLICE;
processes[i].remaining_time -= TIME_SLICE;
}
}
}
}
}
int main() {
Process processes[NUM_PROCESSES] = {
{1, 0, 10, 10, 0, 0, 0},
{2, 1, 6, 6, 0, 0, 0},
{3, 2, 8, 8, 0, 0, 0},
{4, 3, 4, 4, 0, 0, 0}
};
calculateTime(processes, NUM_PROCESSES);
for (int i = 0; i < NUM_PROCESSES; i++) {
printf("P%d 完成时间: %d, 周转时间: %d, 等待时间: %d\n",
processes[i].pid,
processes[i].completion_time,
processes[i].turnaround_time,
processes[i].waiting_time);
}
return 0;
}
输出结果
根据输入数据和时间片轮转调度算法的规则,输出结果如下:
P1 完成时间: 28, 周转时间: 28, 等待时间: 18
P2 完成时间: 22, 周转时间: 21, 等待时间: 15
P3 完成时间: 26, 周转时间: 24, 等待时间: 16
P4 完成时间: 16, 周转时间: 13, 等待时间: 9
5.1.6结论
通过时间片轮转调度算法,每个进程都能公平地获得CPU资源,并且算法能够计算出每个进程的完成时间、周转时间和等待时间。这对于实现操作系统中的进程调度是非常重要的。
习题引导
本章节给大家带来各个题目的详细介绍与解释,并给予大家提示以帮助大家更好地理解题目。
主要内容
- 矩阵相乘 - 矩阵
- 2D卷积操作 - 矩阵
- 矩阵原地转置 - 矩阵
- 包含0的行列进行矩阵置零 - 矩阵
- 查找矩阵中第K个最小的元素 - 矩阵
- 编写一个内核模块求最大值 - 内核模块
- 编写一个内核模块启动一个定时器 - 内核模块
- 编写一个内核模块创建一个虚拟字符设备 - 内核模块
- 编写一个内核模块实现一个简单的文件操作函数 - 内核模块
- 内联汇编实现斐波那契数列 - RISC-V基础指令
- 内联汇编实现整数数组求和 - RISC-V基础指令
- 内联汇编实现查找数组最大值 - RISC-V基础指令
- 内联汇编实现判断数组是否有序 - RISC-V基础指令
- 内联汇编实现数组目标元素个数 - RISC-V基础指令
- 模拟FIFO页面置换算法 - 操作系统
- 模拟LRU页面置换算法 - 操作系统
- 获取容器主机名 - 操作系统
- 简单虚拟地址到物理地址的转换 - 操作系统
- 模拟时间片轮转调度算法 - 操作系统
- 模拟虚拟内存限制 - 操作系统
矩阵相乘
矩阵相乘是线性代数中的一项基本操作,它在图像处理、机器学习、物理模拟等多个领域都有广泛的应用。在本题目中,参与者需要实现一个矩阵相乘的功能,并将结果矩阵输出。
此题可参照第四章 矩阵与卷积算法中的矩阵与线性代数
题目要求
- 实现一个名为
multiply的函数,用于计算两个矩阵的乘积。 - 矩阵乘函数由以下结构表示:
int **multiply(int **A, int ASize, int *AColSize, int **B, int BSize, int *BColSize, int *returnSize, int **returnColumnSizes);
示例
假设有两个矩阵 A 和 B,调用 multiply 函数后,返回的新矩阵应该是:
30 24 18
84 69 54
138 114 90
输入
- 两个矩阵 A 和 B,每个矩阵由逗号分隔的数值表示,例如:
矩阵 A:1,2,3,4,5,6,7,8,9 矩阵 B:9,8,7,6,5,4,3,2,1
输出
- 打印相乘后的矩阵,例如:
Result: 30 24 18 84 69 54 138 114 90
代码介绍
-
main.c 文件包含了主函数,用于解析命令行参数,分配矩阵内存,调用
multiply函数,并打印结果矩阵。 -
matrix_mul.c 文件包含了
multiply函数的实现,以及一个辅助函数printMatrix用于打印矩阵。
代码提示
- 在
main.c中,使用parseMatrix函数解析字符串形式的矩阵到整数指针数组。 multiply函数在matrix_mul.c中实现,但似乎存在问题,因为它没有实现矩阵相乘的逻辑,只是进行了内存分配和返回了结果矩阵的列数。printMatrix函数用于打印矩阵,它接受矩阵的指针、行数和列数作为参数。
注意事项
- 确保
multiply函数正确实现了矩阵相乘的逻辑。 - 检查内存分配是否正确,避免内存泄漏。
- 确保输入的矩阵符合题目要求的维度,以便正确进行矩阵乘法。
- 参与者需要根据题目要求,完成
multiply函数的实现,并确保代码的正确性和效率。同时,需要注意内存管理,避免在程序中引入内存泄漏。
2D 卷积操作
2D 卷积操作是图像处理和计算机视觉中的一项关键技术,广泛应用于图像滤波、特征提取等场景。本题目要求参与者实现一个2D卷积函数,用于计算输入矩阵与卷积核的卷积结果。
此题可参照第四章 矩阵与卷积算法中的卷积算法
题目要求
- 实现
convolution2D函数,计算输入矩阵与卷积核的卷积。 - 函数定义:
void convolution2D(int input[5][5], int kernel[3][3], int output[3][3], int inputSize, int kernelSize);
示例
- 输入矩阵:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 - 卷积核:
1 0 -1 0 -1 0 -1 0 1 - 调用
convolution2D(input, kernel, output, 5, 3)后,输出矩阵应为:-6 -6 -6 -6 -6 -6 -6 -6 -6
输入
- 输入矩阵和卷积核矩阵,以逗号分隔的数值表示,例如:
输入矩阵:1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25 卷积核矩阵:1,0,-1,1,0,-1,1,0,-1
输出
- 打印卷积后的矩阵,例如:
Result: -6 -6 -6 -6 -6 -6 -6 -6 -6
代码介绍
-
convolution.c 文件包含
convolution2D函数的实现,但当前代码仅完成了初始化输出矩阵和卷积核半径的计算,卷积运算尚未实现。 -
main.c 文件包含主函数,用于解析命令行参数,调用
convolution2D函数,并打印卷积结果。
详细提示信息
-
convolution2D 函数实现:
- 计算卷积核半径
kernelRadius。 - 初始化输出矩阵
output为全零。 - 通过嵌套循环遍历输入矩阵的每个元素,应用卷积核进行卷积运算。
- 计算卷积核半径
-
main 函数解析:
- 检查命令行参数数量。
- 使用
parseMatrix函数解析输入矩阵和卷积核。 - 调用
convolution2D函数执行卷积运算。 - 打印卷积结果。
-
parseMatrix 函数:
- 使用
strtok函数解析字符串,将数值转换为整数并填充到矩阵中。
- 使用
注意事项
- 确保
convolution2D函数正确实现卷积运算逻辑。 - 注意卷积核中心与输入矩阵对应位置的对齐方式。
- 考虑边界条件,确保卷积核不会超出输入矩阵边界。
- 避免内存泄漏,合理分配和释放内存。
- 参与者需要根据题目要求,完成
convolution2D函数的实现,确保卷积运算的正确性。同时,注意代码的健壮性和内存管理。通过解析命令行参数和打印结果,展示卷积运算的实际效果
矩阵原地转置
矩阵的原地转置是指在不使用额外存储空间的情况下,直接将一个矩阵转置。对于一个 ( N \times N ) 的矩阵,原地转置意味着交换对角线元素以及对称位置的元素,空间复杂度为 ( O(1) )。
此题可参考第四章 矩阵与卷积算法中的矩阵转置。
题目要求
- 实现
transposeInPlace函数,对一个 ( N \times N ) 的矩阵进行原地转置。
示例
假设输入矩阵为:
1 2 3
4 5 6
7 8 9
执行原地转置后,输出矩阵应为:
Transposed Matrix:
1 4 7
2 5 8
3 6 9
输入
- 一个 ( N \times N ) 的矩阵,以字符串形式输入,矩阵中的元素由逗号分隔。
输出
- 转置后的矩阵,每行元素由空格分隔。
代码介绍
-
matrix_trans.c 文件包含
transposeInPlace函数的框架,但当前尚未实现转置逻辑。 -
main.c 文件包含主函数,用于解析命令行参数,调用
transposeInPlace函数,并打印转置后的矩阵。
详细提示信息
-
transposeInPlace 函数实现:
- 需要交换矩阵对角线元素以及对称位置的元素。
- 使用两个嵌套循环遍历矩阵,对于每个元素,如果其行索引和列索引之和不等于 ( N - 1 ),则与其对称元素交换。
-
main 函数解析:
- 检查命令行参数数量。
- 使用
parseMatrix函数解析输入的矩阵字符串。 - 调用
transposeInPlace函数执行原地转置。 - 打印转置后的矩阵。
-
parseMatrix 函数:
- 解析输入的矩阵字符串,将字符串中的数值填充到矩阵中。
- 注意处理字符串中的逗号和空格。
注意事项
- 确保
transposeInPlace函数正确实现原地转置逻辑,不使用额外存储空间。 - 考虑矩阵的对称性质,避免重复交换元素。
- 确保
parseMatrix函数能够正确解析各种格式的输入字符串。 - 参与者需要根据题目要求,完成
transposeInPlace函数的实现,确保矩阵能够正确原地转置。同时,注意代码的健壮性和正确性。通过解析命令行参数和打印结果,展示原地转置的实际效果。
包含 0 的行列进行矩阵置零
题目介绍
本题目要求实现一个算法,用于将矩阵中所有值为0的元素所在的行和列都置为0。这是一个常见的问题,通常出现在面试和算法竞赛中,考察对矩阵操作和空间复杂度的理解。
题目要求
- 实现
setZeroes函数,该函数接收一个矩阵的指针、矩阵的大小以及每行的列数数组,将矩阵中值为0的元素所在的行和列都置为0。
输入
- 矩阵的大小
matrixSize。 - 每行的列数数组
matrixColSize。 - 矩阵的值,以一维数组的形式提供。
输出
- 修改后的矩阵,其中所有值为0的元素所在的行和列都被置为0。
示例
假设输入矩阵为:
1 0 3
4 5 0
7 8 9
执行 setZeroes 函数后,输出矩阵应为:
1 0 0
0 5 0
7 0 9
代码介绍
-
main.c 文件包含主函数,用于处理命令行输入,分配矩阵内存,调用
setZeroes函数,并打印原始和修改后的矩阵。 -
matrix_zero.c 文件包含
setZeroes函数的框架,以及辅助函数printMatrix和freeMatrix。
详细提示信息
-
setZeroes 函数实现:
- 使用额外的数组
row和col来记录哪些行和列需要被置0。 - 遍历矩阵,标记
row和col中相应的元素。 - 根据
row和col的标记,将矩阵中相应的行和列置0。
- 使用额外的数组
-
main 函数解析:
- 检查命令行参数数量是否正确。
- 分配内存给
matrixColSize和matrix。 - 解析命令行参数,填充矩阵值。
- 调用
setZeroes函数。 - 打印原始和修改后的矩阵。
- 释放分配的内存。
-
printMatrix 函数:
- 打印矩阵的当前状态。
-
freeMatrix 函数:
- 释放矩阵占用的内存。
注意事项
- 确保
setZeroes函数在修改矩阵前正确记录了需要置0的行和列。 - 注意内存分配和释放,避免内存泄漏。
- 考虑空间复杂度,尽量减少额外空间的使用。
- 参与者需要根据题目要求,完成
setZeroes函数的实现,确保能够正确地将矩阵中为0的元素所在的行和列都置为0。同时,注意代码的健壮性和内存管理。通过命令行参数和打印结果,展示算法的实际效果。
查找矩阵中第 K 个最小的元素
题目介绍
本题目要求实现一个算法,用于找出给定矩阵中的第 ( k ) 小的元素。矩阵是一个由不同长度的行组成的二维数组,这种类型的矩阵问题在编程和算法设计中很常见,特别是在处理大数据集时。
题目要求
- 实现
kthSmallest函数,该函数接收矩阵的指针、矩阵的大小、每行的列数数组以及整数 ( k ),返回矩阵中的第 ( k ) 小的元素。
输入
- 矩阵的大小
matrixSize。 - 整数 ( k ),表示需要找的第 ( k ) 小元素的索引(从1开始)。
- 每行的列数数组
matrixColSize。 - 矩阵的值,以一维数组的形式提供。
输出
- 第 ( k ) 小的元素值。
示例
假设输入矩阵为:
5 3
1 4 2
6 7 8
对于 ( k = 5 )(即我们要找的第5小的元素),输出应为:
The 5th smallest element in the matrix is: 4
代码介绍
-
main.c 文件包含主函数,用于处理命令行输入,分配矩阵内存,调用
kthSmallest函数,并打印原始矩阵和第 ( k ) 小的元素。 -
matrix_kmin.c 文件包含
kthSmallest函数的框架,以及辅助数据结构最小堆(MinHeap)的实现。
详细提示信息
-
kthSmallest 函数实现:
- 使用最小堆来存储矩阵中的元素,以找到第 ( k ) 小的元素。
- 遍历矩阵,将每个元素插入到最小堆中。
- 从最小堆中提取前 ( k - 1 ) 个元素,堆顶剩下的元素即为所求。
-
main 函数解析:
- 检查命令行参数数量是否正确。
- 分配内存给
matrixColSize和matrix。 - 解析命令行参数,填充矩阵值。
- 调用
kthSmallest函数。 - 打印原始矩阵和第 ( k ) 小的元素。
- 释放分配的内存。
-
MinHeap 数据结构:
- 实现了一个最小堆,用于存储和操作矩阵中的元素。
- 提供了
createMinHeap、minHeapify、extractMin和insertMinHeap等函数。
注意事项
- 确保
kthSmallest函数正确实现,使用最小堆来找到第 ( k ) 小的元素。 - 注意内存分配和释放,避免内存泄漏。
- 考虑时间复杂度和空间复杂度,尽量减少不必要的操作。
- 参与者需要根据题目要求,完成
kthSmallest函数的实现,确保能够正确地找出矩阵中的第 ( k ) 小的元素。同时,注意代码的健壮性和内存管理。通过命令行参数和打印结果,展示算法的实际效果。
编写一个内核模块求最大值
题目介绍
本题目要求编写一个Linux内核模块,该模块能够接收一个整数数组作为输入,计算并输出数组中所有元素的最大值。这是一个很好的练习,可以帮助理解Linux内核模块的编写和基本的数组操作。
本题可参考第五章 Linux内核模块中的编写一个简单的内核模块与内核模块传参
题目要求
- 编写一个内核模块。
- 接收一个以逗号分隔的整数字符串作为输入。
- 计算输入数组中的最大值。
- 输出结果。
输入
- 一个以逗号分隔的整数字符串,例如:"8,3,12,6,20"
输出
- 数组中的最大值,对于上述输入,输出应为:20
示例
- 输入:[8, 3, 12, 6, 20]
- 输出:20
代码介绍
-
max_value.c 文件包含了内核模块的实现。
- 定义了模块参数
input_str,用于接收输入的字符串。 - 实现了
parse_input函数,用于解析字符串并填充到整数数组arr中。 - 实现了
max_value函数,用于找出数组中的最大值,但当前实现尚未完成。
- 定义了模块参数
-
模块初始化函数
max_init在模块加载时执行,调用parse_input和max_value函数,并打印最大值。 -
模块退出函数
max_exit在模块卸载时执行,打印卸载信息。
详细提示信息
-
max_value 函数实现:
- 需要遍历整个数组,使用一个变量记录最大值。
- 与数组中的每个元素比较,并更新最大值。
-
parse_input 函数:
- 使用
strsep和kstrtoint函数解析字符串。 - 将解析后的整数填充到数组
arr中,并记录数组大小arr_size。
- 使用
-
模块参数:
- 使用
module_param定义了input_str参数。 - 使用
MODULE_PARM_DESC提供了参数的描述。
- 使用
-
内存管理:
- 使用
kstrdup和kfree管理内存,避免内存泄漏。
- 使用
-
错误处理:
- 对于输入字符串为空或解析失败的情况,模块初始化函数返回
-EINVAL。
- 对于输入字符串为空或解析失败的情况,模块初始化函数返回
注意事项
- 确保
max_value函数正确实现最大值查找逻辑。 - 注意模块参数的使用和内存管理。
- 考虑使用内核日志函数
printk进行适当的错误和信息输出。 - 参与者需要根据题目要求,完成
max_value函数的实现,确保内核模块能够正确地找出并输出数组中的最大值。同时,注意代码的健壮性和内存管理。通过内核模块的编写和测试,加深对Linux内核模块开发的理解。
编写一个内核模块启动一个定时器
题目介绍
本题目要求参与者编写一个Linux内核模块,该模块使用内核定时器(timer)来实现周期性的任务执行。内核定时器是Linux内核提供的一种机制,允许在指定的时间后执行某些操作,或者按照一定的时间间隔重复执行操作。
本题可参考第五章 Linux内核模块中的实现计时器
题目要求
- 编写一个内核模块,使用内核定时器实现周期性执行。
- 定时器应该在模块加载后5秒触发,并在每次触发时打印当前的jiffies(系统启动以来的时钟节拍数)。
- 每次触发后,定时器应重新设置为再次5秒后触发。
输入
无特定输入要求。
输出
- 定时器每次触发时,打印一条包含当前jiffies的消息。
示例
- 触发示例消息:
Timer callback function called [jiffies值].
代码介绍
-
timer.c 文件包含了内核模块的实现。
- 定义了一个
struct timer_list名为my_timer,用于管理定时器。 - 实现了
my_timer_callback函数,该函数在定时器触发时被调用,并打印当前的jiffies值。 - 设置了
my_timer_callback函数为my_timer的回调函数。
- 定义了一个
-
模块初始化函数
timer_init在模块加载时执行,需要在这里设置定时器。 -
模块退出函数
timer_exit在模块卸载时执行,删除定时器并打印卸载信息。
详细提示信息
-
定时器设置:
- 使用
mod_timer函数设置定时器的触发时间。 - 定时器首次设置需要在
timer_init函数中完成,并在5秒后触发。 - 在
my_timer_callback函数中重新设置定时器,以实现周期性触发。
- 使用
-
模块初始化和退出:
- 在
timer_init中设置定时器并打印加载信息。 - 在
timer_exit中删除定时器并打印卸载信息。
- 在
-
内核日志:
- 使用
printk函数打印内核日志信息。
- 使用
-
错误处理:
- 目前代码中没有错误处理,但实际编写时应注意可能的错误情况。
注意事项
- 确保定时器正确设置并能够周期性触发。
- 注意模块的初始化和退出函数中定时器的设置和删除。
- 使用内核日志函数
printk进行适当的信息输出。 - 参与者需要根据题目要求,完成定时器的设置和周期性任务的实现。通过编写内核模块,加深对Linux内核定时器机制的理解,并掌握内核模块的编写和测试流程。
编写一个内核模块创建一个虚拟字符设备
题目介绍
本题目要求编写一个Linux内核模块,用于创建一个虚拟字符设备。当用户读取这个设备时,它会返回一个固定的字符串。这个练习有助于理解Linux内核模块的编写,特别是字符设备驱动的创建和使用。
本题可参考第五章 Linux内核模块中的创建字符设备
题目要求
- 编写一个内核模块,创建一个虚拟字符设备。
- 当用户读取该设备时,返回预设的字符串。
输入
无特定输入要求。
输出
- 当用户读取设备时,输出字符串 "hello"。
示例
- 设备读取示例输出:
hello
代码介绍
-
chardev.c 文件包含了内核模块的实现。
- 定义了设备名称
DEVICE_NAME和默认消息DEFAULT_MESSAGE。 - 使用
module_param定义了模块参数message,允许在加载模块时传入自定义消息。
- 定义了设备名称
-
实现了以下函数:
dev_open:设备打开时调用,重置消息指针。dev_release:设备关闭时调用,打印关闭信息。dev_read:从设备读取数据时调用,需要实现读取逻辑。
-
定义了
file_operations结构体fops,包含设备的操作方法。 -
模块初始化函数
chardev_init用于注册字符设备和打印相关信息。 -
模块退出函数
chardev_exit用于注销字符设备。
详细提示信息
-
字符设备注册:
- 使用
register_chrdev函数注册字符设备,获取主设备号major。
- 使用
-
模块参数:
- 使用
module_param定义了message参数,允许用户在加载模块时通过insmod命令传入自定义消息。
- 使用
-
文件操作:
- 实现
dev_open函数,设备打开时重置消息指针。 - 实现
dev_read函数,从设备读取消息。需要使用vsscanf或类似方法将message_ptr指向的字符串复制到用户空间的buffer中,并返回读取的字节数。
- 实现
-
内存管理:
- 注意不要直接将用户空间的指针与内核空间的指针相互赋值,应使用适当的内存访问函数。
-
错误处理:
- 在
chardev_init中检查register_chrdev的返回值,如果注册失败,打印错误信息并返回错误代码。
- 在
注意事项
- 确保
dev_read函数正确实现,能够返回预期的字符串。 - 注意模块参数的使用和字符设备的注册与注销。
- 使用内核日志函数
printk进行适当的信息输出。 - 参与者需要根据题目要求,完成虚拟字符设备的实现,确保能够通过模块参数传入消息,并在用户读取设备时返回该消息。通过编写内核模块,加深对Linux内核字符设备驱动的理解,并掌握内核模块的编写和测试流程。
编写一个内核模块实现一个简单的文件操作函数
题目介绍
本题目要求编写一个Linux内核模块,实现对文件的基本操作,包括打开、读取、写入和关闭文件。这是一个基础练习,有助于理解Linux内核模块中文件操作的实现方式。
本题可参考第五章 Linux内核模块中的实现简单文件操作
题目要求
- 编写一个内核模块。
- 实现文件的打开、读取、写入、关闭操作。
- 在控制台输出操作结果。
输入
无特定输入要求。
输出
- 成功打开文件时输出:
File operation successful - 打开失败时输出:
Failed to open file
代码介绍
-
fileop.c 文件包含了内核模块的实现。
- 定义了文件名
FILE_NAME和用于操作的文件指针file_ptr。
- 定义了文件名
-
模块初始化函数
fileop_init在模块加载时执行,需要在这里实现文件操作逻辑。 -
模块退出函数
fileop_exit在模块卸载时执行,关闭文件并打印信息。
详细提示信息
-
文件操作:
- 使用
filp_open函数尝试打开文件,该函数需要文件名、访问模式和其他标志。 - 检查
filp_open的返回值,如果成功,将返回的struct file *指针赋值给file_ptr。
- 使用
-
读取和写入文件:
- 如果需要,使用
vfs_read或vfs_write函数实现文件的读取和写入操作。
- 如果需要,使用
-
错误处理:
- 如果文件打开失败,打印错误信息。
-
模块初始化和退出:
- 在
fileop_init中实现文件操作,并根据操作结果打印相应信息。 - 在
fileop_exit中检查file_ptr是否非空,如果是,则调用filp_close关闭文件,并打印关闭信息。
- 在
-
内核日志:
- 使用
printk函数根据不同情况打印内核日志信息。
- 使用
注意事项
- 确保正确处理文件打开操作的成功与失败。
- 注意模块的初始化和退出函数中文件操作的完整性。
- 使用内核日志函数
printk进行适当的信息输出。 - 参与者需要根据题目要求,完成文件操作的实现,确保能够正确打开文件并在适当的时候关闭文件。通过编写内核模块,加深对Linux内核文件操作的理解,并掌握内核模块的编写和测试流程。
使用内联 RISCV 汇编实现计算斐波那契数列的第 n 个数
题目介绍
本题目要求参与者使用RISC-V汇编语言内联在C程序中,实现计算斐波那契数列第n项的函数。斐波那契数列是一个每一项都是前两项和的序列,通常定义为F(0) = 0, F(1) = 1, 且对于n > 1, 有 F(n) = F(n-1) + F(n-2)。
本题可参考第六章 RISC-V架构内联汇编全部小节内容。
题目要求
- 使用RISC-V汇编语言内联在C函数中。
- 实现计算斐波那契数列第n项的值。
- 编写的汇编代码需要替换C函数中的PLACEHOLDER。
输入
- 命令行参数,一个整数n,表示斐波那契数列的位置。
输出
- 斐波那契数列第n项的值。
示例
- 如果输入是
5,则输出应该是5,因为斐波那契数列的第5项是5。
代码介绍
-
main.c 文件包含了主函数和
fibonacci函数的C包装器。main函数处理命令行参数,并调用fibonacci函数打印结果。fibonacci函数使用内联汇编实现,其中包含了多个PLACEHOLDER,需要用正确的RISC-V汇编指令替换。
-
内联汇编使用GCC的扩展语法,其中:
"li"指令用于将立即数加载到寄存器。"addi"指令用于将一个立即数加到寄存器。"add"指令用于将两个寄存器的值相加。"mv"指令用于将一个寄存器的值移动到另一个寄存器。"bne"指令用于比较两个寄存器,如果不相等则跳转到指定标签。"j"指令用于无条件跳转。
详细提示信息
-
内联汇编替换:
- 使用RISC-V汇编指令替换PLACEHOLDER,完成斐波那契数列的计算。
- 对于
n == 0,应返回0,使用"li %0, 0"并跳转至结束标签。 - 对于
n == 1,应返回1,使用"li %0, 1"并跳转至结束标签。 - 在循环中,使用
"add"更新斐波那契数列的值,并使用"mv"或"addi"更新寄存器。
-
控制流:
- 使用
"bne"指令控制循环,直到n减至0。
- 使用
-
寄存器使用:
%0用于存储结果。%1用于存储参数n,并在循环中递减。t0,t1,t2为临时寄存器,用于计算。
-
编译与测试:
- 使用
gcc编译器编译程序,并确保RISC-V汇编语法正确。
- 使用
注意事项
- 确保替换的汇编指令逻辑正确,能够正确计算斐波那契数列的值。
- 注意内联汇编的语法和寄存器使用。
- 确保程序能够正确处理命令行参数。
- 参与者需要根据题目要求,使用RISC-V汇编语言完成斐波那契数列的计算。通过这个练习,可以加深对RISC-V汇编语言和内联汇编使用的理解。
使用内联 RISCV 汇编实现整数数组求和
题目介绍
本题目要求参与者编写一个C语言函数 calculate_sum,该函数使用内联RISC-V汇编来计算一个整数数组中所有元素的和。然后,编写一个程序调用该函数并输出结果。
本题可参考第六章 RISC-V架构内联汇编全部小节内容。
题目要求
- 实现一个C语言函数
calculate_sum,使用内联RISC-V汇编。 - 函数接受一个整数数组
arr和数组的长度n。 - 计算并返回数组中所有元素的和。
输入
- 一个整数数组
arr,以逗号分隔,例如1,2,3,4,5。 - 一个整数
n,表示数组的长度。
输出
- 按照格式
Sum of array elements is result输出,其中result是数组中所有元素的和。
示例
- 如果输入数组是
1,2,3,4,5且n = 5,则输出应该是Sum of array elements is 15。
代码介绍
-
main.c 文件包含了主函数和
calculate_sum函数的C包装器。main函数处理命令行参数,解析数组字符串,并调用calculate_sum函数打印结果。calculate_sum函数使用内联汇编实现,其中包含了多个PLACEHOLDER,需要用正确的RISC-V汇编指令替换。
-
内联汇编使用GCC的扩展语法,其中:
"li"指令用于将立即数加载到寄存器。"lw"指令用于从内存加载值到寄存器。"addi"指令用于将一个立即数加到寄存器。"add"指令用于将两个寄存器的值相加。"mv"指令用于将一个寄存器的值移动到另一个寄存器。"bge"指令用于比较两个寄存器,并在第一个大于等于第二个时跳转。
详细提示信息
-
内联汇编替换:
- 使用RISC-V汇编指令替换
calculate_sum函数中的PLACEHOLDER。 - 对于循环结束条件,使用
"bge"指令比较索引寄存器t0和n寄存器。 - 使用
"lw"从数组中加载元素到临时寄存器t2。 - 使用
"add"将t2的值累加到result寄存器t1。 - 使用
"addi"将数组指针arr的地址递增以指向下一个元素。
- 使用RISC-V汇编指令替换
-
数组解析:
- 在
main函数中,使用strtok函数解析逗号分隔的数组字符串。
- 在
-
错误处理:
- 检查命令行参数的数量和格式。
- 确保输入的数组元素数量与
n匹配。
-
编译与测试:
- 使用
gcc编译器编译程序,并确保RISC-V汇编语法正确。
- 使用
注意事项
- 确保替换的汇编指令逻辑正确,能够正确计算数组的和。
- 注意内联汇编的语法和寄存器使用。
- 确保程序能够正确处理命令行参数和数组解析。
- 参与者需要根据题目要求,使用RISC-V汇编语言完成数组求和的计算。通过这个练习,可以加深对RISC-V汇编语言和内联汇编使用的理解,并掌握如何在C语言中嵌入汇编代码来优化性能关键部分。
使用内联 RISCV 汇编实现查找整数数组最大值
题目介绍
本题目要求参与者编写一个C语言函数 find_max,该函数使用内联RISC-V汇编来找出一个整数数组中的最大值。然后,编写一个程序调用该函数并输出结果。
本题可参考第六章 RISC-V架构内联汇编全部小节内容。
题目要求
- 实现一个C语言函数
find_max,使用内联RISC-V汇编。 - 函数接受一个整数数组
arr和数组的长度n。 - 找出并返回数组中的最大值。
输入
- 一个整数数组
arr,以逗号分隔,例如10,20,30,40。 - 一个整数
n,表示数组的长度。
输出
- 按照格式
Maximum element in array is result输出,其中result是数组中的最大值。
示例
- 如果输入数组是
10,20,30,40且n = 4,则输出应该是Maximum element in array is 40。
代码介绍
-
main.c 文件包含了主函数和
find_max函数的C包装器。main函数处理命令行参数,解析数组字符串,并调用find_max函数打印最大值。find_max函数使用内联汇编实现,其中包含了多个PLACEHOLDER,需要用正确的RISC-V汇编指令替换。
-
内联汇编使用GCC的扩展语法,其中:
"li"指令用于将立即数加载到寄存器。"lw"指令用于从内存加载值到寄存器。"mv"指令用于将一个寄存器的值移动到另一个寄存器。"bge"指令用于在比较操作中,当大于或等于时跳转。
详细提示信息
-
内联汇编替换:
- 使用RISC-V汇编指令替换
find_max函数中的PLACEHOLDER。 - 将
max初始化为数组的第一个元素值,使用"lw"指令从数组加载并使用"mv"移动到t1。 - 在循环中,使用
"lw"从数组中加载当前元素到t2,使用"bge"判断并可能更新max。 - 使用
"addi"更新数组指针arr和循环计数器t0。
- 使用RISC-V汇编指令替换
-
数组解析:
- 在
main函数中,使用strtok函数解析逗号分隔的数组字符串。
- 在
-
错误处理:
- 检查命令行参数的数量和格式。
- 确保输入的数组元素数量与
n匹配。
-
编译与测试:
- 使用
gcc编译器编译程序,并确保RISC-V汇编语法正确。
- 使用
注意事项
- 确保替换的汇编指令逻辑正确,能够正确找出数组的最大值。
- 注意内联汇编的语法和寄存器使用。
- 确保程序能够正确处理命令行参数和数组解析。
- 参与者需要根据题目要求,使用RISC-V汇编语言完成找出数组最大值的计算。通过这个练习,可以加深对RISC-V汇编语言和内联汇编使用的理解,并掌握如何在C语言中嵌入汇编代码来优化性能关键部分。
使用内联 RISCV 汇编实现判断给定数组是否有序
题目介绍
本题目要求参与者编写一个C语言函数 is_sorted,该函数使用内联RISC-V汇编来检查一个整数数组是否按非降序排列。接着,编写一个程序调用该函数并根据结果输出相应的信息。
本题可参考第六章 RISC-V架构内联汇编全部小节内容。
题目要求
- 实现C语言函数
is_sorted,使用内联RISC-V汇编。 - 函数接收一个整数数组
arr和数组的长度n。 - 检查数组是否有序,即对于每个索引 i(0 ≤ i < n-1),arr[i] ≤ arr[i+1]。
输入
- 一个整数数组
arr,以逗号分隔,如1,2,3,4,5。 - 一个整数
n,表示数组的长度。
输出
- 如果数组有序,输出
Array is sorted.。 - 如果数组无序,输出
Array is not sorted.。
示例
- 对于输入
n = 5和数组arr = [1,2,3,4,5],输出应为Array is sorted.。
代码介绍
-
main.c 文件包含了主函数和
is_sorted函数的C包装器。main函数处理命令行参数,解析数组字符串,并调用is_sorted函数打印检查结果。is_sorted函数使用内联汇编实现,其中包含多个PLACEHOLDER,需要用正确的RISC-V汇编指令替换。
-
内联汇编使用GCC的扩展语法,其中:
"li"指令用于加载立即数到寄存器。"lw"指令用于从内存加载值到寄存器。"bge"指令用于在比较操作中,当大于或等于时跳转。"addi"指令用于将立即数加到寄存器。"mv"指令用于将一个寄存器的值移动到另一个寄存器。
详细提示信息
-
内联汇编替换:
- 使用RISC-V汇编指令替换
is_sorted函数中的PLACEHOLDER。 - 使用
"lw"指令加载数组元素到寄存器t2和t3。 - 使用
"bge"指令比较两个寄存器的值,并在当前元素大于下一个元素时跳转到sorted标签。 - 使用
"li"设置结果为0,表示数组无序,并跳转到end标签。 - 使用
"addi"更新数组指针和循环计数器。
- 使用RISC-V汇编指令替换
-
数组解析:
- 在
main函数中,使用strtok函数解析逗号分隔的数组字符串。
- 在
-
错误处理:
- 检查命令行参数的数量和格式。
- 确保输入的数组元素数量与
n匹配。
-
编译与测试:
- 使用
gcc编译器编译程序,并确保RISC-V汇编语法正确。
- 使用
注意事项
- 确保替换的汇编指令逻辑正确,能够正确检查数组的有序性。
- 注意内联汇编的语法和寄存器使用。
- 确保程序能够正确处理命令行参数和数组解析。
- 参与者需要根据题目要求,使用RISC-V汇编语言完成数组有序性的检查。通过这个练习,可以加深对RISC-V汇编语言和内联汇编使用的理解,并掌握如何在C语言中嵌入汇编代码来优化性能关键部分。
使用内联 RISCV 汇编实现给定数组目标元素个数
题目介绍
本题目要求编写一个C语言函数 count_occurrences,该函数使用内联RISC-V汇编来计算一个整数数组中目标值出现的次数。然后,编写一个程序调用该函数并输出结果。
本题可参考第六章 RISC-V架构内联汇编全部小节内容。
题目要求
- 实现C语言函数
count_occurrences,使用内联RISC-V汇编。 - 函数接收一个整数数组
arr、数组的长度n和一个目标值target。 - 计算并返回目标值在数组中出现的次数。
输入
- 一个整数数组
arr,以逗号分隔,例如1,2,3,4,5。 - 一个整数
n,表示数组的长度。 - 一个整数
target,表示要计数的目标值。
输出
- 按照格式
Occurrences of target:OCCURRENCE输出,其中OCCURRENCE是目标值在数组中的出现次数。如果目标值未出现,则输出Occurrences of target:0。
示例
- 对于输入
n = 5,数组arr = [1,2,2,3,2]和target = 2,输出应为Occurrences of target:3。
代码介绍
-
main.c 文件包含了主函数和
count_occurrences函数的C包装器。main函数处理命令行参数,解析数组字符串,调用count_occurrences函数并打印出现次数。count_occurrences函数使用内联汇编实现,包含多个PLACEHOLDER,需要用正确的RISC-V汇编指令替换。
-
内联汇编使用GCC的扩展语法,其中包括:
"li"指令用于将立即数加载到寄存器。"lw"指令用于从内存加载值到寄存器。"beq"指令用于比较两个寄存器的值,并在相等时跳转。"addi"指令用于将立即数加到寄存器。"mv"指令用于将一个寄存器的值移动到另一个寄存器。
详细提示信息
-
内联汇编替换:
- 使用RISC-V汇编指令替换
count_occurrences函数中的PLACEHOLDER。 - 使用
"li"初始化计数器和索引寄存器。 - 使用
"lw"加载数组元素到寄存器,并使用"beq"指令比较是否与目标值相等。 - 使用
"addi"更新计数器和数组索引。
- 使用RISC-V汇编指令替换
-
数组解析:
- 在
main函数中,使用strtok函数解析逗号分隔的数组字符串。
- 在
-
错误处理:
- 检查命令行参数的数量和格式。
- 确保输入的数组元素数量与
n匹配。
-
编译与测试:
- 使用
gcc编译器编译程序,并确保RISC-V汇编语法正确。
- 使用
注意事项
- 确保替换的汇编指令逻辑正确,能够正确计算目标值的出现次数。
- 注意内联汇编的语法和寄存器使用。
- 确保程序能够正确处理命令行参数和数组解析。
- 参与者需要根据题目要求,使用RISC-V汇编语言完成目标值出现次数的计算。通过这个练习,可以加深对RISC-V汇编语言和内联汇编使用的理解,并掌握如何在C语言中嵌入汇编代码来优化性能关键部分。
模拟 FIFO 页面置换算法
题目介绍
本题目要求模拟操作系统中使用的FIFO(先进先出)页面置换算法。FIFO算法是一种简单的页置换策略,它总是替换最早被加载进内存的页面。当页面访问序列给定,以及物理内存中可用的页框数量确定时,模拟页面的加载和置换过程,并在每次页面访问后输出内存中的页面状态。
本题可参考第七章 操作系统常用算法中的FIFO 页面置换算法
题目要求
- 实现
fifo_page_replacement函数,模拟FIFO页面置换算法。 - 处理页面访问序列,并根据物理内存的页框数量进行页面置换。
- 每次页面访问后,输出当前物理内存中的页面状态。
输入
- 第一行:虚拟内存页访问序列(以逗号分隔的整数)。
- 第二行:物理内存的页框数量(整数)。
输出
- 每次页面访问后的物理内存状态,格式为
Access:<page>,Frames:[<frame1>,<frame2>,...]。
示例
- 输入:
0,1,2,0,1,3,0 3 - 输出:
Access:0,Frames:[0,-1,-1] Access:1,Frames:[0,1,-1] Access:2,Frames:[0,1,2] Access:0,Frames:[0,1,2] Access:1,Frames:[0,1,2] Access:3,Frames:[3,1,2] Access:0,Frames:[3,0,2]
代码介绍
-
main.c 文件包含了主函数,用于处理命令行参数并调用
fifo_page_replacement函数。 -
fifo.c 文件应包含
fifo_page_replacement函数的实现,但当前为空,需要编写。 -
fifo.h(未展示)可能包含
fifo_page_replacement函数的声明和任何必要的数据结构。
详细提示信息
-
FIFO算法逻辑:
- 使用队列(或数组)来模拟物理内存中的页框。
- 遍历页面访问序列,对于每个页面访问:
- 如果页面已加载在内存中,则不进行置换。
- 如果页面未加载,检查是否有足够的空闲页框:
- 如果有,加载页面。
- 如果没有,根据FIFO算法置换最早加载的页面,然后加载新页面。
-
内存管理:
- 使用额外的数据结构(如哈希表)来跟踪页面是否已加载。
-
输入处理:
- 在
main.c中,解析命令行参数,获取页面访问序列和页框数量。
- 在
-
输出格式化:
- 在每次页面访问后,按照要求的格式输出当前内存状态。
-
测试:
- 编译程序,并使用示例输入进行测试,验证输出的正确性。
注意事项
- 确保
fifo_page_replacement函数正确实现FIFO置换逻辑。 - 注意内存分配和释放,避免内存泄漏。
- 确保输出格式与题目要求一致。
- 参与者需要根据题目要求,完成
fifo_page_replacement函数的实现,确保能够正确模拟FIFO页面置换算法。通过这个练习,可以加深对操作系统内存管理和页面置换算法的理解。
模拟 LRU 页面置换算法
题目介绍
本题目要求模拟操作系统中使用的LRU(最近最少使用)页面置换算法。LRU算法是一种性能优异的页置换策略,它根据页面的使用频率来决定哪些页面应该被置换出物理内存。当一个页面被访问时,如果物理内存已满,LRU算法会替换掉最长时间未被访问的页面。
本题可参考第七章 操作系统常用算法中的LRU 页面置换算法
题目要求
- 实现
lru_page_replacement函数,模拟LRU页面置换算法。 - 处理页面访问序列,并根据物理内存的页框数量进行页面置换。
- 每次页面访问后,输出当前物理内存中的页面状态。
输入
- 第一行:虚拟内存页访问序列(以逗号分隔的整数)。
- 第二行:物理内存的页框数量(整数)。
输出
- 每次页面访问后的物理内存状态,格式为
Access:<page>,Frames:[<frame1>,<frame2>,...]。
示例
- 输入:
0,1,2,0,1,3,0 3 - 输出:
Access:0,Frames:[0,-1,-1] Access:1,Frames:[0,1,-1] Access:2,Frames:[0,1,2] Access:0,Frames:[0,1,2] Access:1,Frames:[0,1,2] Access:3,Frames:[0,1,3] Access:0,Frames:[0,1,3]
代码介绍
main.c
主函数文件,用于处理命令行参数并调用 lru_page_replacement 函数。它使用 strdup 函数复制输入的页面访问序列,并检查内存分配是否成功。
int main (int argc, char *argv[]) {
// ...
lru_page_replacement(queue_frames, num);
return EXIT_SUCCESS;
}
lru.c
应包含 lru_page_replacement 函数的实现,但当前为空,需要编写。该函数需要模拟LRU页面置换算法。
void lru_page_replacement(char *queue_frames, int num) {
// TODO
}
lru.h
包含 lru_page_replacement 函数的声明和任何必要的数据结构。
详细提示信息
LRU算法逻辑
- 使用数据结构(如链表或哈希表)来跟踪页面的访问顺序和内存中的页面状态。
- 遍历页面访问序列,对于每个页面访问:
- 如果页面已加载在内存中,更新其为最近访问的状态。
- 如果页面未加载,检查是否有足够的空闲页框:
- 如果有,加载页面。
- 如果没有,根据LRU算法找到并置换最长时间未被访问的页面,然后加载新页面。
内存管理
- 确保使用合适的数据结构来有效模拟页面的加载和置换过程。
输入处理
- 在
main.c中,解析命令行参数,获取页面访问序列和页框数量。
输出格式化
- 在每次页面访问后,按照要求的格式输出当前内存状态。
测试
- 编译程序,并使用示例输入进行测试,验证输出的正确性。
注意事项
- 确保
lru_page_replacement函数正确实现LRU置换逻辑。 - 注意内存分配和释放,避免内存泄漏。
- 确保输出格式与题目要求一致。
- 参与者需要根据题目要求,完成
lru_page_replacement函数的实现,确保能够正确模拟LRU页面置换算法。通过这个练习,可以加深对操作系统内存管理和页面置换算法的理解。
获取容器主机名
题目介绍
本题目要求参与者完成一个C语言程序,该程序的功能是获取并输出当前容器(或虚拟机)的主机名。
本题可参考Linux系统编程基础
题目要求
- 完成给定程序中的
main函数。 - 函数的作用是获取当前环境(容器或虚拟机)的主机名,并将其作为程序输出。
输入
- 无输入要求。
输出
- 应输出当前容器或虚拟机的主机名,例如
admin_virtual_machine。
代码介绍
main.c
主函数文件,需要实现获取主机名的逻辑。
#include <stdio.h>
#include <unistd.h>
int main () {
// TODO
}
详细提示信息
获取主机名
在Unix-like系统中,可以使用系统调用 gethostname 来获取当前主机名。这个函数需要一个字符数组作为参数,并将主机名复制到这个数组中。
使用 gethostname
- 声明一个足够大的字符数组来存储主机名,通常这个数组的大小至少为
HOST_NAME_MAX。 - 调用
gethostname函数,传入字符数组和数组的大小作为参数。 - 检查
gethostname的返回值,确保主机名被成功获取。 - 使用
printf或puts函数输出获取到的主机名。
注意事项
- 确保包含正确的头文件,以便使用
gethostname函数。 - 检查
gethostname的返回值,并对可能的错误进行处理。 - 确保输出的主机名是正确的,并且符合题目要求的格式。
- 参与者需要根据题目要求,使用
gethostname函数完成main函数的实现,确保程序能够正确获取并输出当前容器或虚拟机的主机名。通过这个练习,可以加深对Unix系统调用和主机名获取机制的理解。
简单虚拟地址到物理地址的转换
题目介绍
本题目要求实现一个虚拟地址到物理地址的转换过程,这是操作系统内存管理中的一个重要概念。通过给定的页表和虚拟地址,参与者需要完成地址转换的函数实现。
本题可参考第一章 虚拟内存与物理内存管理
题目要求
- 实现
translate_address函数,将虚拟地址转换为物理地址。 - 假设页大小为 4KB,页表是一个包含32位地址的数组。
输入
- 一个无符号 32 位整数,表示虚拟地址(十六进制格式)。
输出
- 一个无符号 32 位整数,表示对应的物理地址(十六进制格式)。
示例
- 输入:
0x00002234 - 输出:
Physical_Address:0x20002234
代码介绍
main.c
主函数文件,用于处理命令行参数并调用 translate_address 函数。
int main (int argc, char *argv[]) {
// ...
uint32_t physical_address = translate_address(virtual_address);
printf("Physical_Address:0x%x\n", physical_address);
return EXIT_SUCCESS;
}
v2p.c
包含 translate_address 函数的实现,需要根据页表完成地址转换。
uint32_t page_table[] = {
// 模拟页表项
};
uint32_t translate_address(uint32_t virtual_address) {
// TODO
}
v2p.h
头文件,包含宏定义和函数声明。
#ifndef _V2P_H__
#define _V2P_H__
#include <stdint.h>
#define PAGE_SIZE 4096
// ...
uint32_t translate_address(uint32_t virtual_address);
#endif
详细提示信息
地址转换逻辑
- 根据虚拟地址确定页表项索引。
- 使用索引从页表中获取物理页帧基地址。
- 将虚拟地址的偏移量加到物理页帧基地址上,得到完整的物理地址。
使用页表
- 页表
page_table是一个数组,每个元素代表一个页的物理页帧基地址。
示例转换
- 假设虚拟地址为
0x00002234:- 页号为
0x00002,页内偏移为0x234。 - 页表项索引为
0x00002 / PAGE_SIZE。 - 页表项值为
page_table[索引]。 - 物理地址为
page_table[索引] + 页内偏移。
- 页号为
注意事项
- 确保正确处理页号和页内偏移的计算。
- 考虑页表项未找到的情况,并进行适当处理。
- 参与者需要根据题目要求,完成
translate_address函数的实现,确保能够正确地将虚拟地址转换为物理地址。通过这个练习,可以加深对操作系统内存管理和地址转换机制的理解。
模拟时间片轮转调度算法
题目介绍
本题目旨在模拟操作系统中的时间片轮转(Round Robin, RR)调度算法。时间片轮转是一种公平的进程调度策略,它通过为每个进程分配固定长度的时间片来实现CPU时间的分配。
本题可参考第七章 操作系统常用算法中的模拟时间片轮转调度算法
题目要求
- 补充实现
calculateTimes函数,根据时间片轮转算法计算每个进程的完成时间、周转时间和等待时间。
输入
- 程序中硬编码了所有数据,包括时间片长度、进程数量、每个进程的到达时间和运行时间。
输出
- 计算并输出每个进程的完成时间、周转时间和等待时间。
示例
- 给出的进程列表和时间片长度下,输出类似如下结果:
P1: 完成时间: 28, 周转时间: 28, 等待时间: 18 P2: 完成时间: 22, 周转时间: 21, 等待时间: 15 P3: 完成时间: 26, 周转时间: 24, 等待时间: 16 P4: 完成时间: 16, 周转时间: 13, 等待时间: 9
代码介绍
main.c
主函数文件,包含了进程数组的定义和调用 calculateTimes 函数的逻辑。
int main() {
// ...
calculateTimes(processes, n, time_slice);
for (int i = 0; i < n; i++) {
printf("P%d:%d,%d,%d\n", processes[i].pid, processes[i].completion_time,
processes[i].turnaround_time, processes[i].waiting_time);
}
return EXIT_SUCCESS;
}
RR.c
包含 calculateTimes 函数的实现,该函数需要根据时间片轮转算法填充进程结构体中的相关字段。
void calculateTimes(Process *processes, int n, int time_slice) {
// TODO
}
RR.h
头文件,定义了进程结构体 Process 和 calculateTimes 函数的声明。
typedef struct {
// ...
} Process;
void calculateTimes(Process *processes, int n, int time_slice);
详细提示信息
时间片轮转算法逻辑
- 维护一个就绪队列来存储所有等待执行的进程。
- 将CPU时间分配给队首进程,长度为时间片。
- 如果进程在时间片内完成,则将其移出队列。
- 如果进程未完成,则将其移动到队列末尾,并继续处理下一个进程。
计算指标
- 完成时间:进程实际完成执行的时间点。
- 周转时间:从进程到达到完成的总时间(完成时间 - 到达时间)。
- 等待时间:进程在就绪队列中等待的时间(周转时间 - 运行时间)。
注意事项
- 确保正确处理进程的到达时间和运行时间。
- 考虑进程可能在一个时间片内完成或需要多个时间片完成。
- 维护一个当前时间变量,以跟踪模拟的进度。
- 参与者需要根据题目要求,完成
calculateTimes函数的实现,确保能够正确模拟时间片轮转调度算法,并计算出每个进程的相关指标。通过这个练习,可以加深对操作系统进程调度机制的理解。
模拟虚拟内存限制
题目介绍
本题目要求编写一个C程序,用于演示如何在Unix-like系统中设置进程的内存限制,并运行一个子进程来测试这个限制。这涉及到资源限制的概念,是操作系统中进程管理的一个重要方面。
本题可参考Linux系统编程基础
题目要求
- 实现
set_memory_limit函数,设置进程的内存限制。 - 实现
run_child_process函数,创建并运行一个子进程,并为其设置内存限制。 - 子进程应尝试分配超出限制的内存,并观察结果。
输入
- 子进程尝试分配的内存大小(在
child_program.c中硬编码为120MB)。
输出
- 子进程因超出内存限制而失败的信号或退出状态。
代码介绍
child_program.c
子进程的程序,尝试分配指定大小的内存。
void allocate_memory(size_t size_in_mb) {
// ...
}
int main() {
allocate_memory(120); // 尝试分配120MB内存
return 0;
}
main.c
主进程的程序,设置内存限制并运行子进程。
void set_memory_limit(rlim_t memory_limit) {
// 设置内存限制
}
void run_child_process(rlim_t memory_limit, const char *program_path) {
// 运行子进程并设置内存限制
}
int main() {
// 设置内存限制为100MB并运行子进程
run_child_process(memory_limit, program_path);
return 0;
}
详细提示信息
设置内存限制
- 使用
setrlimit函数设置进程的资源限制,具体是RLIMIT_AS(进程的地址空间限制)。
运行子进程
- 使用
fork创建子进程。 - 在子进程中调用
set_memory_limit设置内存限制。 - 使用
execl替换子进程的映像,运行child_program。 - 在父进程中等待子进程结束,并根据其退出状态给出相应的输出。
注意事项
- 确保
setrlimit正确设置内存限制,注意资源限制的结构体rlimit的设置方式。 - 子进程的内存分配失败时,应正确捕捉并输出错误信息。
- 父进程应正确解释子进程的退出状态,并给出清晰的输出。
- 参与者需要根据题目要求,完成内存限制设置和子进程运行的相关函数实现。通过这个练习,可以加深对操作系统资源限制和进程管理的理解。