使用 GCC 13 编译包含 RVV Intrinsic 的程序
0. 总结
- GCC 13 仅支持 RVV 0.11 (但相对容易获取), GCC 14 则支持完整的 RVV 1.0
- GCC 的 RVV Intrinsic 是通过编译器实现的
riscv_vector.h中没有相关 Intrinsic 与数据类型的声明, 这导致 Intellisense 等代码补全无法直接工作
- GCC 的 RVV Intrinsic 需要
__riscv前缀 - Linux 内核已经合并了对 RVV 的支持
1. 获取 GCC 13
目前 Debian 12 源中的 gcc-riscv64-unknown-elf 版本还在 12.2.0, 不支持 RVV Intrinsic. 所以我们需要从 riscv-collab/riscv-gnu-toolchain 根据自己的系统版本下载最新的 nightly release. 下载后解压并将路径添加到 PATH, 再看看我们拿到的 GCC 版本:
horizon@horizon-vm-ubuntu20:~$ riscv64-unknown-elf-gcc --version
riscv64-unknown-elf-gcc () 13.2.0
Copyright (C) 2023 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
GCC 13 仅支持 RVV 0.11, GCC 14 则支持 RVV 1.0 . 这里我们出于简便起见不再自行编译 GCC (Debian sid 中 gcc-riscv64-unknown-elf 版本也只有 13.2.0; Arch 上有 riscv64-elf-gcc 14.1.0).
2. RVV Intrinsics
目前最新的 RVV Intrinsic 规范的版本是 1.0 RC0, 可以在这里获取. 每个 Intrinsic 函数名称可以分为如下部分:
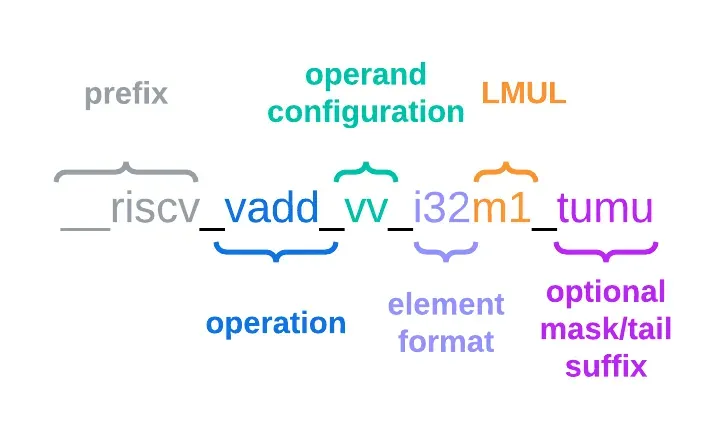
- 前缀:
__risc_v - 操作
- 操作数:
v表示向量,x表示标量 - 元素格式:
i整数,fIEEE-754 浮点数 LMUL寄存器设定LMUL决定了将若干个向量寄存器视为一个整体, 例如LMUL=2时, v0 将表示 v0v1, v2 表示 v2v3;LMUL=4时, v0 将表示 v0v1v2v3, v4 表示 v4v5v6v7.
- 可选的掩码或后缀
更多关于命名规则的信息可见 Chapter 6. Naming scheme.
通过 __riscv_v_intrinsic 宏, 可以检测编译器对 RVV 的支持情况. 查看 riscv_vector.h, 可以看到这样一段:
/* NOTE: This implementation of riscv_vector.h is intentionally short. It does
not define the RVV types and intrinsic functions directly in C and C++
code, but instead uses the following pragma to tell GCC to insert the
necessary type and function definitions itself. The net effect is the
same, and the file is a complete implementation of riscv_vector.h. */
#pragma riscv intrinsic "vector"
由于不包含 intrinsic 函数以及相应的数据类型, 因此代码提示与补全不能生效 :(
3. 编写一个 RVV demo 并在 qemu 中测试
Vector Add
参考张宇轩同学在RVV C Intrinsic 配置教程中的实例代码, 增加了对拍:
注意这里的 intrinsic 有
__risc_v前缀, 如果你按照张宇轩同学的方法配置的环境的话, 可能需要去掉这些前缀
// Reference: https://pages.dogdog.run/toolchain/riscv_vector_extension.html
// #define __riscv_vector // make VSC happy when reading riscv_vector.h
#include <riscv_vector.h>
#include <stdio.h>
int x[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0};
int y[10] = {0, 9, 8, 7, 6, 5, 4, 3, 2, 1};
int z[10], z_real[10];
void vec_add_rvv(int* dst, int* lhs, int* rhs, size_t avl) {
vint32m2_t vlhs, vrhs, vres;
for (size_t vl; (vl = __riscv_vsetvl_e32m2(avl));
avl -= vl, lhs += vl, rhs += vl, dst += vl) {
vlhs = __riscv_vle32_v_i32m2(lhs, vl);
vrhs = __riscv_vle32_v_i32m2(rhs, vl);
vres = __riscv_vadd_vv_i32m2(vlhs, vrhs, vl);
__riscv_vse32_v_i32m2(dst, vres, vl);
}
}
void vec_add_real(int* dest, int* lhs, int* rhs, size_t vlen) {
for (size_t i = 0; i < vlen; i++) {
dest[i] = lhs[i] + rhs[i];
}
}
void print_vec(int* v, size_t vlen, char* msg) {
printf("%s={ ", msg);
for (size_t i = 0; i < vlen; i++) {
printf("%d, ", v[i]);
}
printf("}\n");
}
int main(int argc, char const* argv[]) {
// check RVV support
#ifndef __riscv_v_intrinsic
printf("RVV NOT supported in this compiler\n");
return 0;
#endif
vec_add_rvv(z, x, y, 10);
vec_add_real(z_real, x, y, 10);
print_vec(x, 10, "x[10]");
print_vec(y, 10, "y[10]");
for (size_t i = 0; i < 10; i++) {
if (z[i] != z_real[i]) {
printf("==========\nTest FAILED: pos %d mismatch\n", i);
print_vec(z, 10, "z[10]");
print_vec(z_real, 10, "z_real[10]");
return -1;
}
}
print_vec(z, 10, "z[10]");
printf("==========\nTest PASSED\n");
return 0;
}
使用 riscv64-unknown-elf-gcc -O -march=rv64gcv vadd_test.c -o vadd_out 编译, qemu-riscv64 -cpu rv64,v=true,vlen=128,vext_spec=v1.0 ./vadd_out 运行:
horizon@horizon-vm-ubuntu20:~$ qemu-riscv64 -cpu rv64,v=true,vlen=128,vext_spec=v1.0 ./rvv_out
x[10]={ 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, }
y[10]={ 0, 9, 8, 7, 6, 5, 4, 3, 2, 1, }
z[10]={ 1, 11, 11, 11, 11, 11, 11, 11, 11, 1, }
==========
Test PASSED
可以看到 RVV Intrinsic 成功发挥了作用, 并且计算结果与我们手动计算完全相同~
One Step Further
在 这里, 我们可以看到 vec_add_rvv 函数反汇编后 (或者说汇编前? 总之是它对应的 RISC-V 汇编) 的结果.
vector_add:
beq a3,zero,.L1
.L3:
vsetvli a5,a3,e32,m1,ta,ma
vle32.v v24,0(a1)
vle32.v v25,0(a2)
vfadd.vv v24,v24,v25
vse32.v v24,0(a0)
sub a3,a3,a5
slli a5,a5,2
add a1,a1,a5
add a2,a2,a5
add a0,a0,a5
bne a3,zero,.L3
.L1:
ret
beq 对应 for 循环的初值边界: 若向量长度等于零, 则直接返回.
vsetvli a5, a3, e32, m1, ta, ma 设置向量相关的配置: a3 是剩余的元素数,e32 表示每个元素是 32 位, m1 表示每个向量寄存器的长度是 1 倍的标准长度 (也就是说每个寄存器里面都是一个向量), ta 和 ma 分别表示尾部与掩码都是不可知的.
两条 vle32.v 分别从 a1 与 a2 寄存器指向的地址加载一个 32 位的向量到对应的向量寄存器. vfadd.vv 进行两个向量之间的加法, vse32.v 将 v24 中的结果保存到 a0 指向的地址. 之后更新各个地址的值, 进行下一轮加法, 直到所有元素都被计算.
Vector Multiply
类似地, 我们可以使用向量乘法, 这里使用 32 位浮点数, 每个向量由 8 个元素构成.
注意这里的 intrinsic 有
__risc_v前缀, 如果你按照张宇轩同学的方法配置的环境的话, 可能需要去掉这些前缀
#include <riscv_vector.h>
#include <stdio.h>
void vector_mul_rvv(const float *a, const float *b, float *dest, size_t vlen) {
size_t vl;
size_t i = 0;
for (; i < vlen; i += vl) {
// set vector length
vl = __riscv_vsetvl_e32m1(vlen - i);
vfloat32m1_t va = __riscv_vle32_v_f32m1(&a[i], vl);
vfloat32m1_t vb = __riscv_vle32_v_f32m1(&b[i], vl);
vfloat32m1_t vres = __riscv_vfmul_vv_f32m1(va, vb, vl);
__riscv_vse32_v_f32m1(&dest[i], vres, vl);
}
}
void vector_mul_real(const float *a, const float *b, float *dest, size_t vlen) {
for (size_t i = 0; i < vlen; i++) {
dest[i] = a[i] * b[i];
}
}
void print_vec(float *v, size_t vlen, char *msg) {
printf("%s={ ", msg);
for (size_t i = 0; i < vlen; i++) {
printf("%f, ", v[i]);
}
printf("}\n");
}
int main() {
// check RVV support
#ifndef __riscv_v_intrinsic
printf("RVV NOT supported in this compiler\n");
return 0;
#endif
float a[8] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0};
float b[8] = {8.0, 7.0, 6.0, 5.0, 4.0, 3.0, 2.0, 1.0};
float c[8], c_real[8];
vector_mul_rvv(a, b, c, 8);
vector_mul_real(a, b, c_real, 8);
print_vec(a, 8, "a[8]");
print_vec(b, 8, "b[8]");
for (size_t i = 0; i < 8; i++) {
if (c[i] != c_real[i]) {
printf("==========\nTest FAILED: pos %d mismatch\n", i);
print_vec(c, 8, "c[10]");
print_vec(c_real, 8, "c_real[10]");
return -1;
}
}
print_vec(c, 8, "c[10]");
printf("==========\nTest PASSED\n");
return 0;
}
编译: riscv64-unknown-elf-gcc -O -march=rv64gcv rvv_mul.c -o rvv_mul
运行: qemu-riscv64 -cpu rv64,v=true,vlen=128,vext_spec=v1.0 ./rvv_mul
结果:
horizon@horizon-vm-ubuntu20:~$ qemu-riscv64 -cpu rv64,v=true,vlen=128,vext_spec=v1.0 ./rvv_mul
a[8]={ 1.000000, 2.000000, 3.000000, 4.000000, 5.000000, 6.000000, 7.000000, 8.000000, }
b[8]={ 8.000000, 7.000000, 6.000000, 5.000000, 4.000000, 3.000000, 2.000000, 1.000000, }
c[10]={ 8.000000, 14.000000, 18.000000, 20.000000, 20.000000, 18.000000, 14.000000, 8.000000, }
==========
Test PASSED
4. Linux 内核目前对 RVV 的支持
RVV 1.0 的支持 已经被合并到内核.
内核通过 bool has_vector() 检测对 RVV 的支持:
has_vector()->riscv_has_extension_unlikely(RISCV_ISA_EXT_v)->__riscv_isa_extension_available(NULL, ext)->test_bit(bit, bmap) ? true : false, 最终还是以检测特定比特位的形式完成.
4.1 RVV 任务切换
在 arch/riscv/include/asm/switch_to.h#L102 中, 可以看到首先判断是否存在 RVV 支持, 若存在, 则调用 __switch_to_vector(__prev, __next) 完成 RVV 上下文的切换:
- 判断当前任务状态
- 调用
__riscv_v_vstate_save以 8 个一组保存 v0~v31 的值 - 判断下一个任务的状态
- 调用
riscv_v_vstate_set_restore, 同样分组恢复各向量寄存器的值.
99. 更多关于 RVV 的材料
- RVV Intrinsic Viewer: 可以看到 RVV Intrinsics 的定义与功能分析
- RISC-V Vector Programming in C with Intrinsics : 一份很好的 RVV 教程, 包括直接用汇编以及使用 intrinsics
- RISC-V Vector Intrinsic Document: RVV Intrinsic 标准